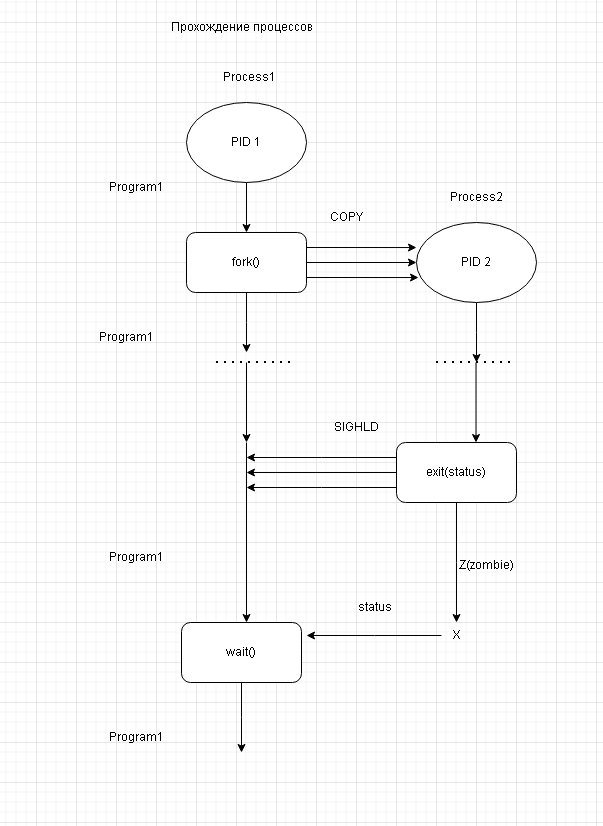
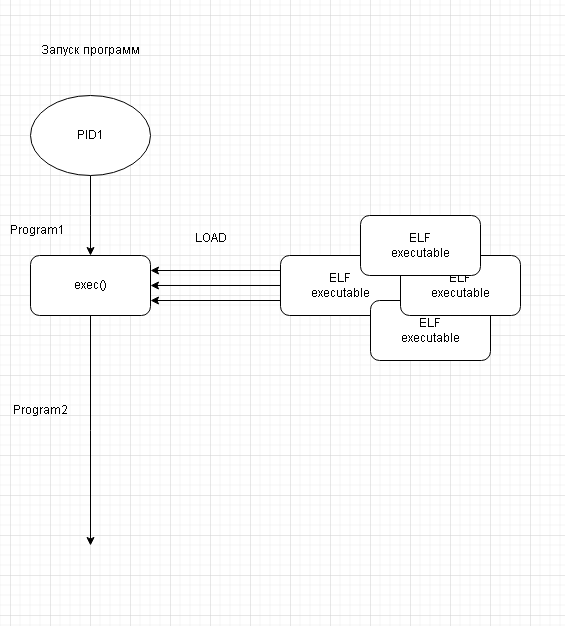
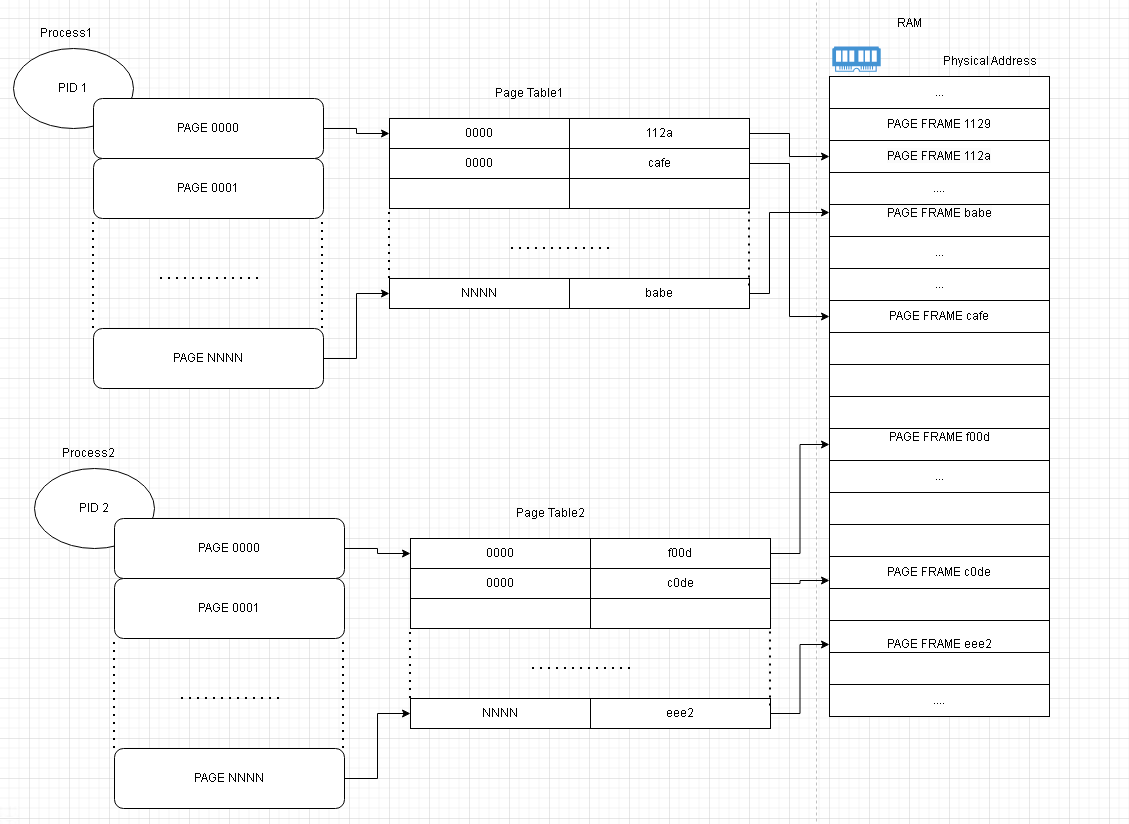
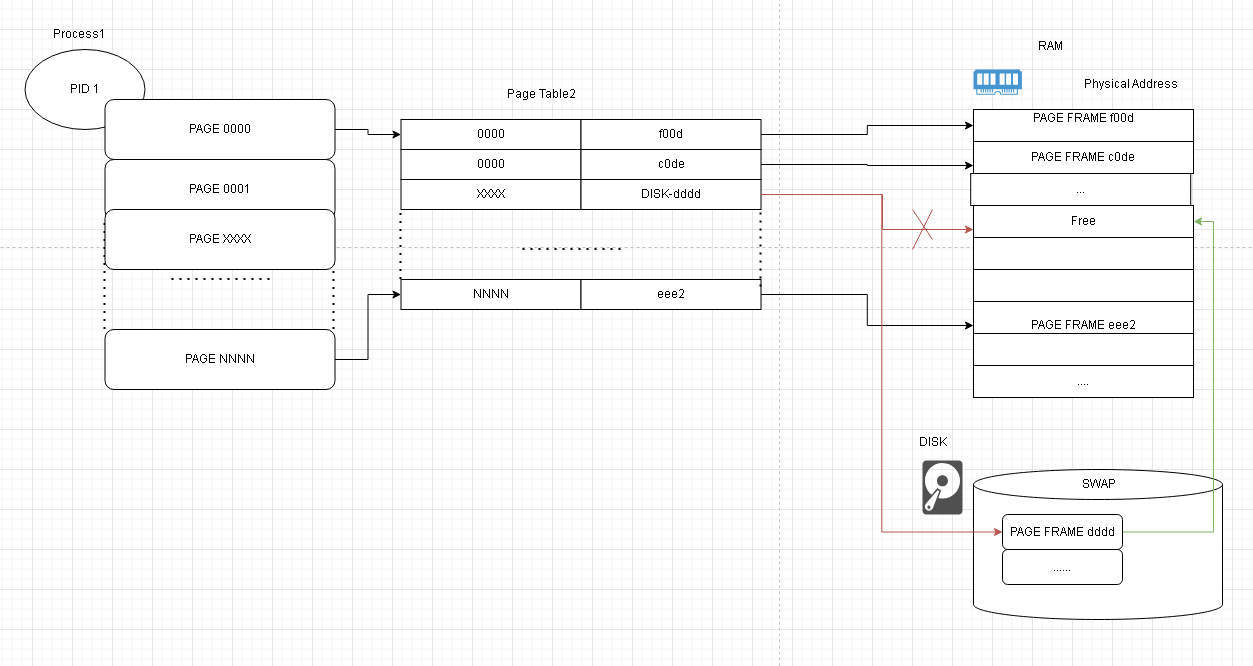
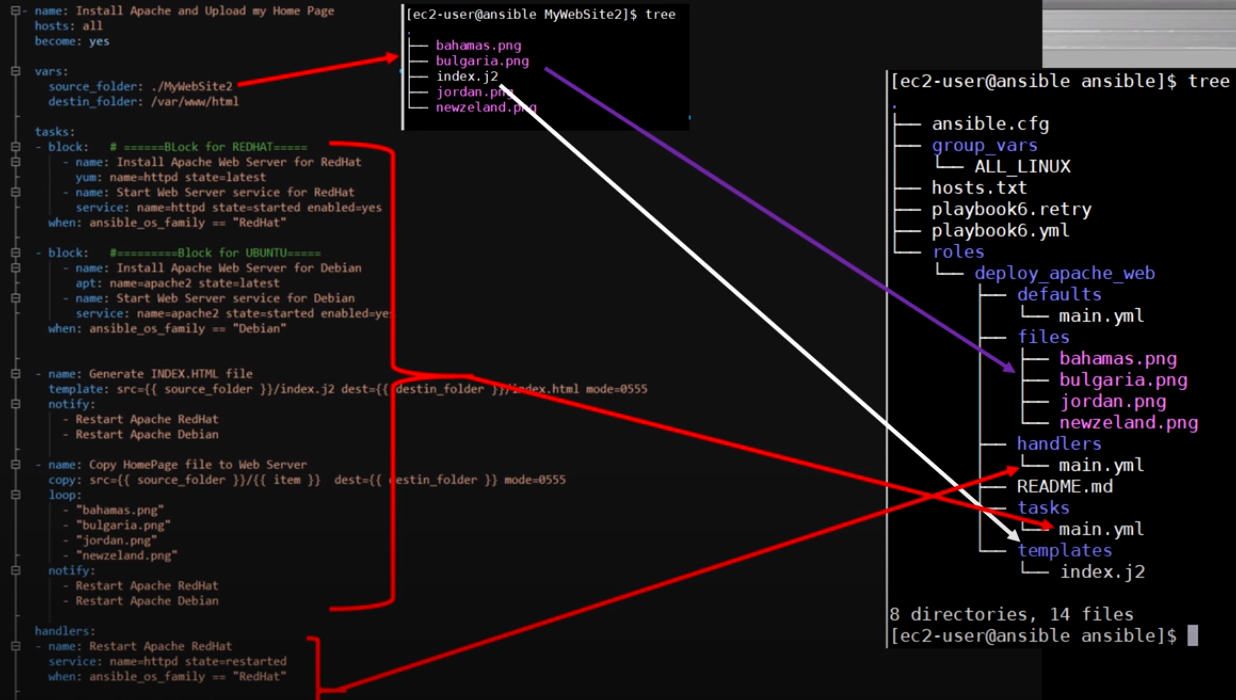
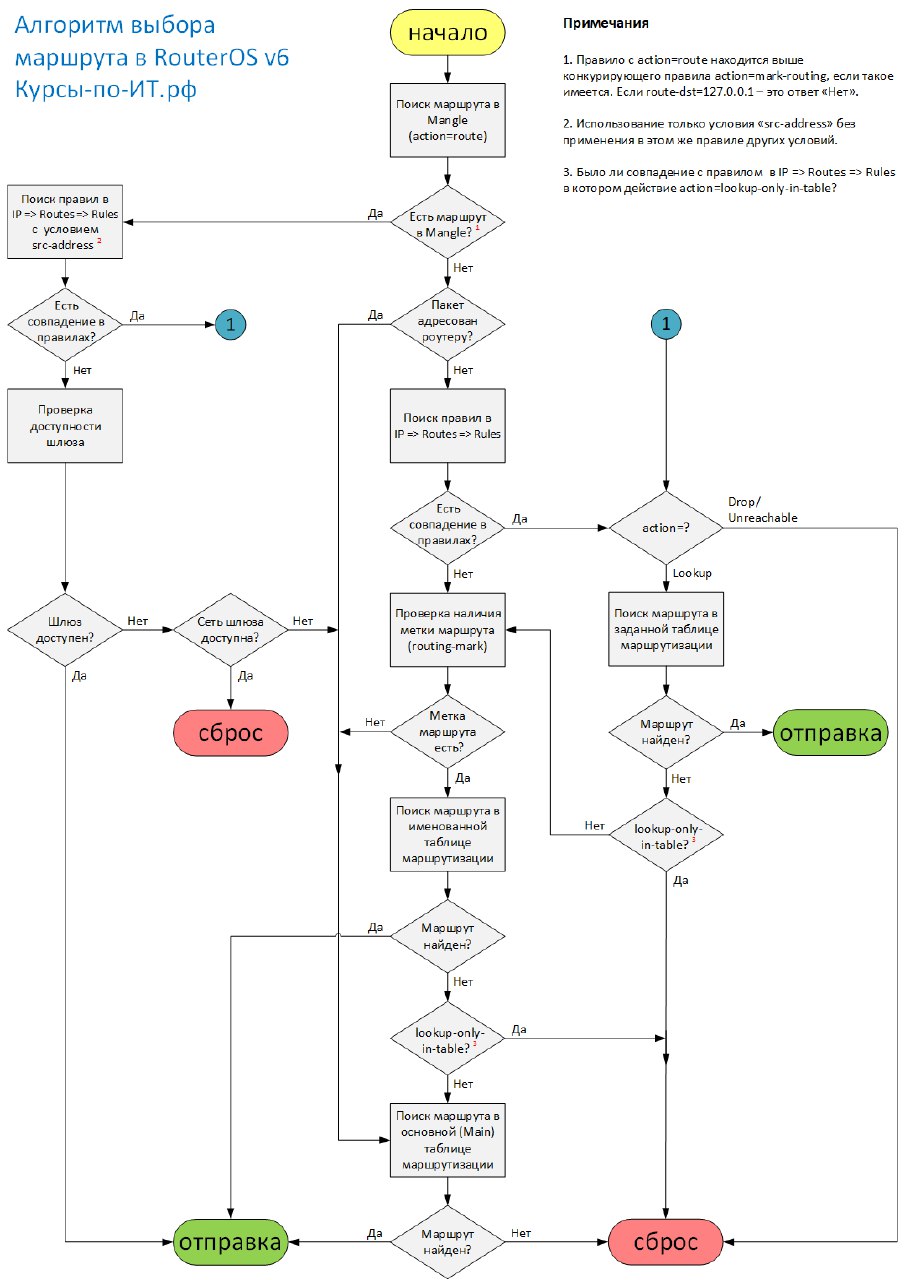
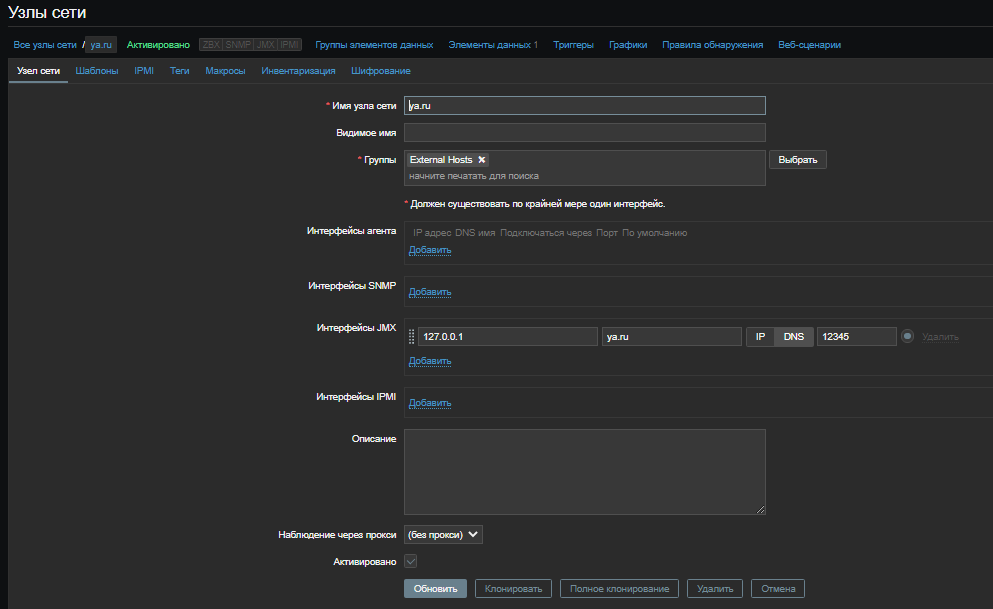
Ссылки:
https://go.dev/play/
https://wiki.archlinux.org/title/Go_(%D0%A0%D1%83%D1%81%D1%81%D0%BA%D0%B8%D0%B9)
https://github.com/b14esh/c-test/tree/main/02_lesson_golang
Установка golang на linux
0. Установка
# debian ubuntu
apt update && apt upgrade && apt install golang
# archlinux
pacman -Sy go
1. Компиляция и запуск файлов
Go — это компилируемый язык.
Первый способ — через команду "go run".
Эта команда компилирует исполняемый файл, запускает его и удаляет.
Этим способом пользуются, когда нужно разово запустить небольшую программу на Go и забыть.
Второй способ — через команду "go build".
Она выполняет компиляцию и создает исполняемый файл в текущей директории.
go build hello.go # Создаем бинарный файл hello.go
В директории с файлом должен появиться новый файл hello.
Можно запустить его как обычный исполняемый файл:
./hello
Пример:
go fmt hello-world.go
go build hello-world.go
go run build hello-world.go
Кросс компиляция под разные платформы:
go mod init hello # Создаем Go-модуль
GOOS=windows GOARCH=386 go build -o hello_windows.exe # Исполняемый файл для Windows
GOOS=windows GOARCH=amd64 go build -o hello_windows64.exe # Файл для Windows с архитектурой x64
GOOS=linux GOARCH=amd64 go build -o hello_linux_amd64 # Файл для linux с архитектурой x64
GOOS=linux GOARCH=arm go build -o hello_linux_arm # Файл для Linux на arm
GOOS=darwin GOARCH=arm64 go build -o hello_mac_arm64 # для mac os
Показать переменные go / рабочее пространство
go env
В языке Go поиск программ и их зависимостей (например, import "пакет"), сначала выполняется в каталогах,
прописанных в переменную $GOPATH, а затем - в переменной $GOROOT (путь установки go, по умолчанию /usr/lib/go).
$GOPATH работает как $PATH и может содержать несколько записей.
Это может быть полезно для отделения пакетов, скачанных через go get, от вашего кода, например GOPATH=$HOME/go:$HOME/mygo
Создать само рабочее пространство:
$ mkdir -p ~/go/src
каталог ~/go/src предназначен для хранения исходных текстов проектов.
При компиляции Go также создаст каталог bin для исполняемых файлов и pkg для кэша отдельных пакетов.
Вы можете добавить ~/go/bin в переменную окружения $PATH для запуска установленных Go-программ:
export PATH="$PATH:$HOME/go/bin"
00. Первый пример:
0. Открываем сайт https://go.dev/play/
1. Вводим код
package main
import "fmt"
func main () {
fmt.Println("Hello, Go")
}
3. Жмем format а потом run
4. Объяснение:
Кнопка Format приводит код в порядок, создаются отступы, выставляются пробелы.
Когда вы распространяете свой код, другие разработчики ожидают, что он будет оформлен в стандартном формате Go.
Это означает стандартное форматирование отступов, пробелов и т. д., чтобы другим людям было проще читать ваш код.
Если в других языках программирования разработчикам приходилось вручную переформатировать свой код, чтобы он соответствовал стилевому руководству,
в Go достаточно выполнить команду go fmt, которая автоматически сделает все за вас.
package main - Эта строка сообщает, что остальной код относится к пакету "main"
import "fmt" - Означает что мы будем использовать код форматирования из пакета "fmt"
Функция main играет особую роль - именно:
func main () {
fmt.Println("Hello, Go") - Эта строка выводит сообщение "Hello,Go!"
}
Для этого она вызывает функцию Println из пакета "fmt"
Пакет представляет собой набор блоков кода, выполняющих похожие операции — например,
форматирование строк или построение графических, изображений.
Директива package задает имя пакета, частью которого станет код этого файла.
В нашем случае используется специальный пакет main; это необходимо для того,
чтобы код можно было запускать напрямую (чаще всего в терминале).
При запуске программа Go ищет функцию с именем main и выполняет ее в первую очередь,
поэтому-то мы и присвоили своей функции имя main.
Структура типичного файла Go
1. Директива package. package main
2. Директива import. import "fmt"
3. Собственно код программы. function main{}
Каждый файл Go должен начинаться с директивы package
Каждый файл Go должен импортировать все пакеты, которые в нем используются
Файлы Go должны импортировать только те пакеты, которые в них используются. (Это ускоряет компиляцию кода!)
Компилятор Go ищет функцию с именем main, чтобы выполнить ее при запуске программы
В Go учитывается регистр символов. fmt.Println — действительное имя, но имени fmt.println не существует
Функция Println не принадлежит пакету main, поэтому перед вызовом функции необходимо указать имя пакета
01. Вызов функций
В нашем примере вызывается функция Println из пакета fmt.
Чтобы вызвать функцию, введите имя функции (в данном случае Println) и пару круглых скобок.
Как и многие функции, Println может получать один или несколько аргументов — значений,
с которыми должна работать функция. Аргументы перечисляются в круглых скобках после имени функции
fmt.Println("First argument", "Second argument")
Хотя функции Println и можно передать несколько аргументов, она может вызываться без них.
Когда мы будем заниматься другими функциями, вы заметите, что они обычно должны получать строго определенное количество аргументов.
Если аргументов будет слишком мало или слишком много, то вы получите сообщение об ошибке, в котором будет указано ожидаемое количество аргументов.
В этом случае программу нужно будет исправить.
package main
import "fmt"
func main () {
fmt.Println("First argument", "Second argument")
}
02. Функция Println
При помощи функции Println можно узнать, как идет выполнение программы.
Все аргументы, переданные этой функции, выводятся в терминале (а их значения разделяются пробелами)
После вывода всех аргументов Println переходит на следующую строку в терминале.
(Отсюда суффикс «ln» — сокращение от «line» — в конце имени.)
package main
import "fmt"
func main() {
fmt.Println("One", "Two", "Three")
fmt.Println("Another line")
fmt.Println("End")
}
03. Использование функций из других пакетов. / Возвращаемые значения функций.
Весь код нашей первой программы является частью пакета main, но функция Println принадлежит пакету fmt (сокращение от «format»).
Чтобы в программе можно было вызвать функцию Println, необходимо сначала импортировать пакет, содержащий эту функцию.
// - комментарий
package main
import "fmt" // Пакет fmt необходимо импортировать чтобы вызвать его функции Println
func main() {
fmt.Println("Hello, Go!") // Сообщает что вызываемая функция является частью пакета fmt
}
После того как пакет будет импортирован, вы сможете вызывать функции из этого пакета.
Для этого укажите имя пакета, поставьте точку (.) и введите имя нужной функции.
fmt.Println()
fmt - пакет
.Println() - имя функции
Следующий пример демонстрирует вызов функций из двух других пакетов.
Так как мы собираемся импортировать несколько пакетов, то переходим на альтернативный формат инструкции,
который позволяет перечислять в круглых скобках сразу несколько пакетов, по одному имени пакета в строке.
package main
import (
"math"
"strings"
)
func main() {
math.Floor(2.75)
strings.Title("head first go")
}
!!! Программа ничего не выводит! :)
При вызове функции fmt.Println вам не нужно обмениваться с ней дополнительной информацией.
Вы передаете Println одно или несколько выводимых значений и ожидаете вывод.
Но иногда программа должна вызвать функцию и получить от нее дополнительные данные.
Из-за этого в большинстве языков программирования функции имеют возвращаемые значения,
которые вычисляются функциями и возвращаются на сторону вызова.
Функции math.Floor и strings.Title относятся к числу функций, имеющих возвращаемое значение.
Функция math.Floor получает число с плавающей точкой, округляет его до ближайшего меньшего целого и возвращает полученное число.
А функция strings.Title получает строку, преобразует первую букву каждого слова к верхнему регистру и возвращает полученную строку.
Чтобы увидеть результаты этих вызовов функций, необходимо взять возвращаемые значения и передать их fmt.Println:
package main
import (
"fmt"
"math"
"strings"
)
func main() {
fmt.Println(math.Floor(2.75))
fmt.Println(strings.Title("head first go"))
}
Что делает:
строка: fmt.Println(math.Floor(2.75))
Функция fmt.Println вызывается для возвращаемого значения функции math.Floor.
math.Floor получает число, округляет его в меньшую сторону и возвращает полученное значение.
строка: fmt.Println(strings.Title("head first go"))
Функция fmt.Println вызывается для возвращаемого значения функции strings.Title.
strings.Title получает строку и возвращает новую строку, в которой все слова начинаются с буквы верхнего регистра.
Результат:
2
Head First Go
04. шаблон программы GO
vim test.go
-----------
package main
import "fmt"
func main() {
fmt.Println("hello world")
}
-----------
Проверка:
Производим форматирование скрипта
go fmt test.go
Производим тестовый запуск
go run test.go
Производим сборку
go build test.go
Проверяем еще раз работоспособность
05. Строки
В аргументах Println передавались строки.
Строка представляет собой последовательность байтов, которые обычно представляют символы текста.
Строки можно определять прямо в программе в виде строковых литералов:
компилятор Go интерпретирует текст, заключенный в двойные кавычки, как строку
Открывающая двойная кавычка "Hello, Go!" Закрывающая двойная кавычка
Результат: Hello, Go!
Некоторые управляющие символы, которые неудобно вводить с клавиатуры (символы новой строки, табуляции и т. д.),
внутри строк могут представляться в виде служебных последовательностей: символа «обратный слеш», за которым следует другой символ (или символы).
n Символ новой строки
t Символ табуляции
" Двойная кавычка
Обратный слеш
Пример 0:
"Hello,nGo!"
Результат:
Hello,
Go!
Пример 1:
"Hello, tGo!"
Результат:
Hello, Go!
Пример 2:
""Hello, Go!""
"Hello, Go!"
06. Руны
Если строки обычно используются для представления последовательностей символов,
то руны в языке Go представляют отдельные символы.
Строковые литералы заключаются в двойные кавычки ("),
а рунные литералы записываются в одиночных кавычках (').
В программах Go могут использоваться практически любые символы любых мировых языков, потому что в Go для хранения рун используется стандарт Юникод.
Руны хранятся в виде числовых кодов, а не в виде символов; если передать руну функции fmt.Println, то выведется числовой код, а не исходный символ.
В рунных литералах (как и в строковых) можно использовать служебные последовательности для представления символов, которые неудобно вводить с клавиатуры для включения в программу.
'A' - 65
'B' - 66
'Ж' - 1174
't' - 9
'n' - 10
'' - 92
Пример кода:
package main
import "fmt"
func main() {
fmt.Println('A', 'B', 'Ж', 't', 'n', '')
}
07. Логические значения
Логические величины принимают всего два возможных значения:
true или false.
Они особенно удобны в условных командах, в которых выполнение блока кода зависит от того, истинно или ложно некоторое условие.
Чуть позже разберем...
08. Числа
Числа тоже можно определять прямо в программном коде.
Это еще проще, чем определять строковые литералы: просто введите нужное число.
Как вы вскоре увидите, в языке Go целые числа и числа с плавающей точкой интерпретируются как разные типы.
Помните, что целое число можно отличить от числа с плавающей точкой по разделителю дробной части — точке.
Пример:
42 Целое число.
3.1415 Число с плавающей точкой
Пример в коде:
package main
import "fmt"
func main() {
fmt.Println(0, 3.1415)
}
09. Математические операции и сравнения
Основные математические операторы Go работают так же, как и в большинстве других языков.
оператор + выполняет сложение
оператор - выполняет вычитание
оператор * — умножение
оператор / — деление
Пример кода:
package main
import "fmt"
func main() {
fmt.Println("t1 + 2 =", 1+2, "nt5.4 - 2.2 =", 5.4-2.2, "nt3 * 4 =", 3*4, "nt7.5 / 5 =", 7.5/5)
}
При помощи операторов < и > можно сравнить два значения и проверить, какое из них больше другого.
оператор == (два знака равенства) проверяет, что два значения равны
оператор != проверяет, что два значения не равны
оператор <= проверяет, что второе значение меньше или равно первому
оператор >= проверяет, что второе значение больше или равно первому
Результатом сравнения является логическое значение (true или false)
package main
import "fmt"
func main() {
fmt.Println("t4 < 6 ttt", 4 < 6, "nt4 > 6 ttt", 4 > 6, "nt2 + 2 == 5 tt", 2+2 == 5, "nt2 + 2 !=5 tt", 2+2 != 5, "nt4 < = 6 tt", 4 <= 6, "nt4 >= 4ttt", 4 >= 4)
}
10. Типы
В предыдущем примере кода использовалась функция math.Floor, округляющая число с плавающей точкой с уменьшением,
и функция strings.Title, преобразующая первую букву каждого слова в строке к верхнему регистру.
Логично ожидать, что в аргументе функции Floor передается число, а в аргументе функции Title передается строка.
Но что произойдет, если передать функции Floor строку, а функции Title число?
Go выводит два сообщения об ошибках — по одному для каждого вызова функции, а программа даже не запускается!
Объекты в окружающем мире часто можно разделить на типы в зависимости от того, для чего они используются.
Машину или грузовик нельзя съесть на завтрак, а на омлете или чашке с кукурузными хлопьями не поедешь на работу — они предназначены для другого.
В языке Go используется статическая типизация — это означает, что типы всех значений известны еще до запуска программы.
Функции ожидают, что их аргументы относятся к конкретным типам, а их возвращаемые значения тоже имеют типы (которые могут совпадать или не совпадать с типами аргументов).
Go — язык со статической типизацией.
Если вы используете неправильный тип значения в неподходящем месте, Go сообщит вам об этом.
Пример не правильного использование типов:
package main
import (
"fmt"
"math"
"strings"
)
func main() {
fmt.Println(math.Floor("head first go"))
fmt.Println(strings.Title(2.75))
}
Пример ошибки с неправильными типами:
# command-line-arguments
./00_type_bad.go:10:25: cannot use "head first go" (type untyped string) as type float64 in argument to math.Floor
./00_type_bad.go:11:28: cannot use 2.75 (type untyped float) as type string in argument to strings.Title
11. Узнаем типы значений
Чтобы узнать тип любого значения, передайте его функции TypeOf из пакета reflect.
Давайте узнаем типы некоторых значений, которые уже встречались в примерах программ:
package main
import (
"fmt"
"reflect"
)
func main() {
fmt.Println(reflect.TypeOf(42))
fmt.Println(reflect.TypeOf(3.1234))
fmt.Println(reflect.TypeOf(true))
fmt.Println(reflect.TypeOf("Hello world"))
}
Типы:
int Целое число (не имеющее дробной части)
float64 Число с плавающей точкой.
Тип используется для хранения чисел, имеющих дробную часть.
(Для хранения числа используются 64 бита данных, отсюда суффикс 64 в имени.
Значения типа float64 обеспечивают очень высокую, хотя и не бесконечную точность.)
bool Логическое значение (true или false)
string Строка— последовательность данных, которые обычно представляют символы текста
12. Объявление переменных
В языке Go переменная представляет собой область памяти, в которой хранится значение.
Чтобы к переменной можно было обращаться по имени, используйте объявление переменной.
Объявление состоит из ключевого слова var, за которым следует имя и тип значений, которые будут храниться в переменной.
var quantity int
var length, width float64
var customerName string
После того как переменная будет объявлена, ей можно будет присвоить любое значение этого типа оператором = (один знак равенства):
quantity = 2
customerName = "Damon Cole"
В одной команде можно присвоить значения сразу нескольким переменным.
Для этого перечислите имена переменных слева от = и такое же количество значений в правой части, разделяя их запятыми.
length, width = 1.2, 2.4
После того как переменной будет присвоено значение, вы сможете использовать ее в любом контексте, где может использоваться исходное значение:
package main
import "fmt"
func main() {
var quantity int
var length, width float64
var customerName string
quantity = 4
length, width = 1.2, 2.4
customerName = "Damon Cole"
fmt.Println(customerName)
fmt.Println("has ordered", quantity, "sheets")
fmt.Println("each with an area of")
fmt.Println(length*width, "square meters")
}
Пример 2:
package main
import "fmt"
func main() {
var x1 int
var x2 int
var sumx int
x1 = 500
x2 = 600
sumx = x1+x2
fmt.Println(x1, "+", x2, "=", sumx)
}
Если значение переменной известно заранее, можно объявить переменную и присвоить ей значение в одной строке:
var quantity int = 4
var length, width float64 = 1.2, 2.4
var customerName string = "Damon Cole"
Существующим переменным можно присваивать новые значения, но эти значения должны относиться к тому же типу.
Статическая типизация в Go гарантирует, что переменной не будет случайно присвоено значение неподходящего типа.
Если значение переменной присваивается одновременно с ее объявлением, тип переменной в объявлении обычно не указывают.
Тип значения, присвоенного переменной, будет считаться типом этой переменной.
var quantity = 4
var length, width = 1.2, 2.4
var customerName = "Damon Cole"
fmt.Println(reflect.TypeOf(quantity))
fmt.Println(reflect.TypeOf(length))
fmt.Println(reflect.TypeOf(width))
fmt.Println(reflect.TypeOf(customerName))
Пример:
package main
import "fmt"
func main() {
var x1 int = 700
var x2 int = 800
var sumx = x1+x2
fmt.Println(x1, "+", x2, "=", sumx)
}
13. Нулевые значения
Если переменная объявляется без присваивания значения, то она будет содержать нулевое значение для этого типа.
Для числовых типов нулевое значение равно 0.
Пример:
package main
import "fmt"
func main() {
var myInt int
var myFloat float64
fmt.Println(myInt, myFloat)
}
Но для других типов значение 0 будет недействительным, поэтому нулевое значение для этого типа будет отличаться.
Скажем, для строковых переменных нулевым значением является пустая строка, а для переменных bool — значение false.
Пример:
package main
import "fmt"
func main() {
var myString string
var myBool bool
fmt.Println(myString, myBool)
}
14. Короткие объявления переменных
Вместо того чтобы явно объявлять тип переменной и позднее присваивать ей значение оператором =,
вы совмещаете эти две операции с помощью синтаксиса :=.
Обычное объявление переменной выглядит вот так:
var quantity int = 4
var length, width float64 = 1.2, 2.4
var customerName string = "Damon Cole"
Короткие объявления переменных выглядит так:
quantity := 4
length, width := 1.2, 2.4
customerName := "Damon Cole"
Пример в коде:
package main
import "fmt"
func main() {
quantity := 4
length, width := 1.2, 2.4
customerName := "Damon Cole"
fmt.Println(customerName)
fmt.Println("has ordered", quantity, "sheets")
fmt.Println("each with an area of")
fmt.Println(length*width, "square meters")
}
Явно объявлять тип переменной не обязательно:
тип значения,
присвоенного переменной,
становится типом этой переменной.
Поскольку короткие объявления переменных очень удобны и компактны, они используются чаще обычных объявлений.
Впрочем, время от времени вам будут встречаться обе формы, поэтому важно знать их.
15. Возможные ошибки при добавлении переменных
00. хз что это было....
// не знаю что это было но назвав файл 05_vats_test.go он не запускался :(
// go fmt 05_vats_test.go - выполняло форматирование
// go run 05_vats_test.go - приводило к ошибке "go run: cannot run *_test.go files (05_vars_test.go)"
// go build 05_vats_test.go - молча выполнялся но бинарник не производился
// mv 05_vats_test.go 05_dz.go - но когда я переименовал файл, файл стал выполнятся, сборка также свершилась.
Код для тестов:
package main
import "fmt"
func main() {
quantity := 4
length, width := 1.2, 2.4
customerName := "Damon Cole"
fmt.Println(customerName)
fmt.Println("has ordered", quantity, "sheets")
fmt.Println("each with an area of")
fmt.Println(length*width, "square meters")
}
01. Пример, добавить второе объявление для той же переменной:
quantity := 4
quantity := 4
Ошибка при выполнении:
# command-line-arguments
./07_dd.go:7:11: no new variables on left side of :=
Переменную можно объявить только один раз.
(Хотя при желании ей можно сколько угодно раз присваивать новые значения.
Также можно объявлять другие переменные с тем же именем, но для этого они должны принадлежать другой области видимости.
02. Пример, убрать символ «:» из короткого объявления переменной:
quantity = 4
Ошибка:
# command-line-arguments
./07_dd.go:8:2: undefined: quantity
./07_dd.go:12:29: undefined: quantity
Если вы забудете поставить двоеточие, конструкция
рассматривается как присваивание, а не как объявление,
а переменной, которая не была объявлена, нельзя будет присвоить значение.
03. Пример, присвоить строковое значение переменной int:
quantity := 4
quantity = "a"
Ошибка:
# command-line-arguments
./07_dd.go:10:11: no new variables on left side of :=
./07_dd.go:10:11: cannot use "a" (type untyped string) as type int in assignment
Переменным могут присваиваться только значения того же типа.
04. Пример, количества переменных и значений не совпадают
length, width := 1.2
Ошибка:
# command-line-arguments
./07_dd.go:12:23: assignment mismatch: 2 variables but 1 values
Вы должны предоставить значение для каждой переменной и переменную для каждого значения
05. Пример, удалить код, в котором используется переменная
//fmt.Println(customerName) - например можно просто закомментировать
Ошибка:
# command-line-arguments
./07_dd.go:14:2: customerName declared but not used
Все объявленные переменные должны использоваться в программе.
Если вы удаляете код, в котором используется переменная, необходимо также удалить и объявление.
16. Правила выбора имен для переменных
В Go существует один простой набор правил, применяемых к именам переменных, функций и типов:
!!! Эти правила должны обязательно выполняться на уровне языка
00. Имя должно начинаться с буквы и может содержать любое количество дополнительных букв и цифр.
01. Если имя переменной, функции или типа начинается с буквы верхнего регистра, оно считается экспортируемым и может использоваться в других пакетах, кроме текущего.
(Именно поэтому буква P в fmt.Println имеет верхний регистр:
это нужно для того, чтобы его можно было использовать в main или любом другом пакете.)
Если имя переменной/функции/типа начинается с буквы нижнего регистра, оно считается не экспортируемым.
Такие имена доступны только в текущем пакете.
!!! Но сообщество Go также соблюдает ряд дополнительных соглашений:
02. Если имя состоит из нескольких слов, каждое слово после первого должно начинаться с буквы верхнего регистра,
и они должны следовать друг за другом без разделения пробелами: topPrice, RetryConnection и т. д.
(Первая буква имени имеет верхний регистр только в том случае, если оно должно экспортироваться из пакета.)
Этот стиль записи часто называется верблюжьим регистром, потому что буквы верхнего регистра напоминают горбы у верблюда.
03. Если смысл имени очевиден по контексту, в сообществе Go принято сокращать его: использовать i вместо index, max вместо maximum и т. д.
Примеры:
Нормально:
sheetLength
TotalUnits
i
нарушают соглашения:
sheetlength - Остальные слова должны начинаться с буквы верхнего регистра!
Total_Units - Допустимо, но слова должны записываться подряд!
index - Хорошо бы заменить сокращением!
!!!
Только переменные, функции и типы, имена которых начинаются с буквы верхнего регистра,
считаются экспортируемыми, то есть доступными за пределами текущего пакета.
17. Преобразования
Пример не рабочего кода:
package main
import "fmt"
func main() {
var length float64 = 1.2
var width int = 2
fmt.Println("Area is", length*width)
fmt.Println("length > width?", length > width)
}
При выполнении математических операций и операций сравнения в Go значения должны относиться к одному типу.
Если же типы различаются, то при попытке выполнения кода вы получите сообщение об ошибке.
Ошибка:
# command-line-arguments
./02_badcode.go:8:31: invalid operation: length * width (mismatched types float64 and int)
./02_badcode.go:9:40: invalid operation: length > width (mismatched types float64 and int)
Этот принцип действует и при присваивании новых значений переменным.
Если тип присваиваемого значения не соответствует объявленному типу переменной, вы получите сообщение об ошибке.
package main
import "fmt"
func main() {
var length float64 = 1.2
var width int = 2
length = width
fmt.Println(length)
}
Ошибка:
# command-line-arguments
./03_badcode.go:8:8: cannot use width (type int) as type float64 in assignment
Проблема решается преобразованием значений одного типа к другому типу.
Для этого следует указать тип, к которому должно быть преобразовано значение, а за ним преобразуемое значение в скобках.
var myInt int = 2
float64(myInt)
В результате преобразования вы получите новое значение нужного типа.
Пример кода:
package main
//import "fmt"
import (
"fmt"
"reflect"
)
func main() {
var myInt int = 2
fmt.Println(reflect.TypeOf(myInt))
fmt.Println(reflect.TypeOf(float64(myInt)))
}
Ошибка забыл добавить компонент reflect
# command-line-arguments
./04_pre.go:7:14: undefined: reflect
./04_pre.go:8:14: undefined: reflect
18. Преобразование переменных
Пример не рабочего кода:
package main
import "fmt"
func main() {
var length float64 = 1.2
var width int = 2
fmt.Println("Area is", length*width)
fmt.Println("length > width?", length > width)
}
Исправим код:
package main
import "fmt"
func main() {
var length float64 = 1.2
var width int = 2
fmt.Println("Area is", length*float64(width))
fmt.Println("length > width?", length > float64(width))
}
Теперь математические операции и операции сравнения работают правильно!
Попробуем преобразовать значение int к типу float64 перед присваиванием переменной float64:
var length float64 = 1.2
var width int = 2
length = float64(width) - Преобразование int к типу float64 перед присваиванием переменной float64
fmt.Println(length)
Всегда держите в голове, как преобразования изменяют выходные значения.
Например, переменные float64 могут хранить дробные значения, а переменные int — нет.
Когда вы преобразовываете float64 в int, дробная часть просто отбрасывается!
Это может внести путаницу в любые операции, выполняемые с результирующим значением.
var length float64 = 3.75
var width int = 5
width = int(length) - В результате этого преобразования дробная часть теряется!
fmt.Println(width)
Но если действовать внимательно, вы поймете, что преобразования исключительно важны для работы с Go.
С ними вы сможете совместно использовать несовместимые типы.
Пример:
var price int = 100
var taxRate float64 = 0.08
var tax float64 = float64(price) * taxRate
fmt.Println(tax)
19. Кратко о чем писал выше
go build - Компилирует файлы с исходным кодом в двоичные файлы
go run - Компилирует и запускает программу без сохранения в исполняемом файле
go fmt - Переформатирует исходные файлы с использованием стандартного форматирования Go
go version - Выводит текущую версию Go
- Пакет представляет собой группу взаимосвязанных функций и других блоков кода.
- Прежде чем использовать функции из пакета в файле Go, необходимо импортировать этот пакет.
- Строка — последовательность байтов, обычно представляющих символы текста.
- Руна представляет отдельный символ текста.
- Два самых распространенных числовых типа Go — int (для хранения целых чисел) и float64 (для хранения чисел с плавающей точкой).
- Тип bool используется для хранения логических значений (true или false).
- Переменная представляет собой блок памяти для хранения значения заданного типа.
- Если переменной не присвоено значение, то она содержит нулевое значение для своего типа.
Примеры нулевых значений: 0 для переменных int или float64, "" для строковых переменных.
- Объявление переменной можно совместить с присваиванием ей значения при помощи короткого объявления переменной :=.
- К переменной, функции или типу можно обращаться из кода других пакетов только в том случае, если ее имя начинается с буквы верхнего регистра.
- Команда go fmt автоматически переформатирует исходные файлы по стандартам Go.
Всегда выполняйте команду go fmt для любого кода, который вы собираетесь передавать другим разработчикам.
- Команда go build компилирует исходный код Go в двоичный формат, который может выполняться компьютером.
- Команда go run компилирует и выполняет программу без сохранения в исполняемом файле в текущем каталоге.
Вызовы функций
Функция представляет собой блок кода, который может вызываться в других местах программы.
При вызове функции ей могут передаваться данные в аргументах.
Типы
У всех значений в Go имеется тип, который определяет, для чего могут использоваться эти значения.
Математические операции и сравнения с разными типами запрещены, хотя при необходимости значение можно преобразовать к другому типу.
В переменных Go могут храниться значения только того типа, с которым они были объявлены
20. Вызов методов на примере пакета time
В языке Go можно определять методы: функции, связанные со значениями определенного типа.
Методы Go похожи на связываемые с "объектами" методы других языков программирования, но в Go все проще.
В пакете time определен тип Time, представляющий дату (год, месяц и день) и время (час, минуты, секунды и т. д.).
Каждое значение time.Time содержит метод Year, который возвращает год.
Приведенный ниже код использует этот метод для вывода текущего года:
package main
import (
"fmt"
"time" //Необходимо импортировать пакет «time», чтобы использовать тип time.Time
)
func main() {
var now time.Time = time.Now() //Метод time.Now возвращает значение time.Time, представляющее текущую дату и время.
var year int = now.Year() //У значений time.Time имеется метод Year, который возвращает текущий год.
fmt.Println(year)
}
Функция time.Now возвращает новое значение Time для текущей даты и времени; это значение сохраняется в переменной now.
Затем мы вызываем метод Year для значения, ссылка на которое хранится в now:
now.Year()
| |
| Вызывает метод Year для значения time.Time
Содержит значение time.Time
Метод Yer возвращает целое значение года, которое выводится программой.
Методы — это функции, связанные со значениями конкретного типа
21. Вызов методов на примере пакета strings
Пакет strings содержит тип Replacer, который ищет подстроку в строке и заменяет каждое вхождение этой подстроки в другой строке.
Следующий код заменяет каждый символ # в строке буквой o:
package main
import (
"fmt"
"strings"
)
func main() {
broken := "G# r#cks!"
replacer := strings.NewReplacer("#", "o")
fixed := replacer.Replace(broken)
fmt.Println(fixed)
}
Функция strings.NewReplacer получает аргументы — заменяемую строку ("#") и заменяющую строку ("o") — и возвращает значение strings.Replacer.
Когда мы передаем строку методу Replace значения Replacer, то метод возвращает строку, в которой выполнена указанная замена
офф топ:
Значение. Имя метода.
| |
replacer.Replace(broken)
now.Year()
| |
Значение. Имя метода.
21. Комментарии
Самая распространенная форма комментариев обозначается двумя слешами (//).
Все символы от // до конца строки рассматриваются как часть комментария.
Комментарий // может занимать всю строку или следовать после кода.
// Общее количество виджетов в системе.
var TotalCount int // Должно быть целым числом.
Более редкая форма комментариев занимает несколько строк.
Блочные комментарии начинаются с /* и заканчиваются */, а весь текст между этими маркерами (включая символы новой строки) является частью комментария.
/*
Пакет widget включает все функции,
используемые для работы с виджетами.
*/
22. Получение значения от пользователя
Пример кода:
//Внимание: этот код не будет компилироваться в том виде, в котором он здесь приведен
// pass_fail сообщает, сдал ли пользователь экзамен.
package main
import (
"bufio"
"fmt"
"os"
)
func main() {
fmt.Print("Enter a grade: ")
reader := bufio.NewReader(os.Stdin)
input := reader.ReadString('n') - Возвращает текст, введенный пользователем до нажатия клавиши Enter.
fmt.Println(input) - Вывод введенных данных.
}
Сначала нужно запросить данные у пользователя, и для вывода приглашения используется функция fmt.Print.
(В отличие от Println, функция Print не переходит на новую строку в терминале после вывода сообщения;
таким образом, запрос и введенные данные размещаются в одной строке.)
Затем нам понадобится механизм чтения (получения и хранения) ввода из стандартного ввода программы, в который поступает весь ввод с клавиатуры.
Строка reader := bufio.
NewReader(os.Stdin) сохраняет bufio.Reader в переменной reader, которая сделает это за вас.
Чтобы получить введенные данные от пользователя, мы вызываем метод ReadString для Reader.
Методу ReadString требуется аргумент с руной (символом), отмечающей конец ввода.
Мы хотим прочитать весь текст, введенный пользователем до нажатия Enter, поэтому ReadString передается руна новой строки.
После того как от пользователя будут получены данные, мы просто выводим их.
bufio.Reader - Пока достаточно знать, что это средство позволяет читать текст, введенный с клавиатуры.
Возвращает новое значение bufio.Reader.
|
reader := bufio.NewReader(os.Stdin)
|
Reader читает данные из стандартного ввода (с клавиатуры).
Возвращает данные, введенные пользователем, в виде строки
|
input := reader.ReadString('n')
|
Будет прочитан весь текст до руны новой строки.
Ошибка:
0. go build 00_input.go - при сборке
# command-line-arguments
./00_input.go:14:8: assignment mismatch: 1 variable but reader.ReadString returns 2 values
2. go run 00_input.go - при запуске без сборки
# command-line-arguments
./00_input.go:14:8: assignment mismatch: 1 variable but reader.ReadString returns 2 values
3. из документации / мы должны были увидеть:
multiple-value reader.ReadString() in single-value context
Мы пытаемся прочитать ввод с клавиатуры, но получаем сообщение об ошибке.
Компилятор сообщает о проблеме в следующей строке кода:
input := reader.ReadString('n')
В большинстве языков программирования функции и методы могут возвращать только одно значение, но в Go функция может возвращать сколько угодно значений.
Чаще всего множественные возвращаемые значения в Go используются для возвращения дополнительного значения ошибки, по которому можно определить,
не возникли ли проблемы во время выполнения функции или метода.
Несколько примеров:
bool, err := strconv.ParseBool("true") - Возвращает ошибку, если строку не удается преобразовать в логическое значение.
file, err := os.Open("myfile.txt") - Возвращает ошибку, если файл не удалось открыть.
response, err := http.Get("http://golang.org") - Возвращает ошибку, если страницу не удалось загрузить.
И в чем проблема? Просто добавьте переменную для хранения ошибки и не используйте ее!
Но Go не позволит объявить переменную, если она не используется в программе!!!
input, err := reader.ReadString('n') - не сработает !!! Ошибка "err declared and not used"
Go требует, чтобы каждая объявленная переменная также использовалась где-то в программе.
Если вы добавите переменную err и не проверите ее, программа не будет компилироваться.
Неиспользуемые переменные часто указывают на ошибки в программе;
это один из примеров того, как Go помогает вам выявлять и исправлять ошибки!а
23. Вариант 1. Игнорировать возвращаемое значение ошибки
Если имеется значение, которое должно быть присвоено переменной, но вы не собираетесь его использовать, можно воспользоваться пустым идентификатором Go.
Присваивание значения пустому идентификатору фактически приводит к тому, что оно теряется (а другим читателям вашего кода становится очевидно, что вы поступаете так намеренно).
Чтобы использовать пустой идентификатор, просто введите символ подчеркивания ( _ ) в команде присваивания, где должно использоваться имя переменной.
Попробуем использовать пустой идентификатор вместо обычной переменной err:
// pass_fail сообщает, сдал ли пользователь экзамен.
package main
import (
"bufio"
"fmt"
"os"
)
func main() {
fmt.Print("Enter a grade: ")
reader := bufio.NewReader(os.Stdin)
input, _ := reader.ReadString('n')
fmt.Println(input)
}
24. Вариант 2. Обработка ошибки / пакет log
Игнорирование ошибок не является признаком небрежного кода.
Из предыдущего примера кода:
fmt.Print("Enter a grade: ")
reader := bufio.NewReader(os.Stdin)
input, _ := reader.ReadString('n')
|
Возвращаемый признак ошибки игнорируется!
fmt.Println(input) - Выводит значение, которое может быть недействительным!
В данном случае при возникновении ошибки правильнее было бы предупредить пользователя и прервать выполнение программы.
Пакет log содержит функцию Fatal, которая выполняет обе операции одновременно:
вывод сообщения в терминале и остановку программы.
(В этом контексте «фатальной» называется ошибка, «смертельная» для вашей программы.)
Давайте избавимся от пустого идентификатора "_" и заменим его переменной err, чтобы ошибка снова сохранялась в программе.
Затем воспользуемся функцией Fatal для вывода сообщения об ошибке и прерывания работы программы.
Пример кода:
// pass_fail сообщает, сдал ли пользователь экзамен.
package main
import (
"bufio"
"fmt"
"log"
"os"
)
func main() {
fmt.Print("Enter a grade: ")
reader := bufio.NewReader(os.Stdin)
input, err := reader.ReadString('n')
log.Fatal(err)
fmt.Println(input)
Но при запуске программы обнаружится новая проблема:
Enter a grade: 22
2023/07/26 19:53:50
exit status 1
Такие функции и методы, как ReadString, возвращают значение ошибки nil, что по сути означает «здесь ничего нет».
Другими словами, если переменная err равна nil, значит, ошибки не было.
Но наша программа написана так, что она просто сообщает об ошибке nil!
Что же нужно сделать, чтобы программа завершалась только в том случае, если значение переменной не равно nil?
Для этого можно воспользоваться условными командами, в которых блок кода (одна или несколько команд, заключенных в фигурные скобки)
выполняется только при истинности заданного условия.
if 1 < 2 {
fmt.Println("It's true!")
}
На этом пока стопе нужно разобраться с условными командами
25. Условные команды
Выражение вычисляется, и если полученный результат равен true, то выполняется код в теле условного блока.
Если же результат равен false, условный блок пропускается.
if true {
fmt.Println("I'll be printed!")
}
if false {
fmt.Println("I won't!")
}
Как и многие другие языки, Go поддерживает множественное ветвление в условных командах.
Такие команды записываются в форме if...else if...else.
if grade == 100 {
fmt.Println("Perfect!")
} else if grade >= 60 {
fmt.Println("You pass.")
} else {
fmt.Println("You fail!")
}
Условные команды используют логическое выражение (результат которого равен true или false),
чтобы определить, должен ли выполняться содержащийся в них код.
if 1 == 1 {
fmt.Println("I'll be printed!")
}
if 1 >= 2 {
fmt.Println("I won't!")
}
if 1 > 2 {
fmt.Println("I won't!")
}
if 2 <= 2 {
fmt.Println("I'll be printed!")
}
if 1 < 2 {
fmt.Println("I'll be printed!")
}
if 2 != 2 {
fmt.Println("I won't!")
}
Если код должен выполняться только в том случае, когда условие дает результат false, используйте ! — оператор логического отрицания.
Этот оператор берет значение true и превращает его в false или же берет значение false и превращает его в true.
if !true {
fmt.Println("I won't be printed!")
}
if !false {
fmt.Println("I will!")
}
Если код должен выполняться только в том случае, когда истинны оба условия, используйте оператор && («и»).
А если он должен выполняться лишь тогда, когда истинно хотя бы одно из двух условий, используйте оператор || («или»).
if true && true {
fmt.Println("I'll be printed!")
}
if false || true {
fmt.Println("I'll be printed!")
}
if true && false {
fmt.Println("I won't!")
}
if false || false {
fmt.Println("I won't!")
}
В: Другой язык программирования требует, чтобы условие команды if заключалось в круглые скобки. В Go это не обязательно?
О: Нет. Более того, команда go fmt удалит все круглые скобки, добавленные вами, если только они не используются для определения порядка операций.
26. Условная выдача фатальной ошибки (пакет log) / продолжение
Наша программа сообщает об ошибке и аварийно завершается, хотя данные с клавиатуры были успешно прочитаны.
Сохраняет возвращаемое значение ошибки в переменной.
|
input, err := reader.ReadString('n')
log.Fatal(err) - Сообщаем о возвращаемом значении ошибки
Напоминаю ошибка выглядела вот так:
Enter a grade: 22
2023/07/26 19:53:50
exit status 1
Мы знаем, что если значение в переменной err равно nil, это говорит о том, что данные с клавиатуры были прочитаны успешно.
Теперь, познакомившись с командами if, попробуем обновить код, чтобы сообщение об ошибке и завершение программы происходило только в том случае,
если значение err не равно nil.
Пример кода с обработкой ошибки:
// Выводит строку которую ввели
package main
import (
"bufio"
"fmt"
"log"
"os"
)
func main() {
fmt.Print("Enter a grade: ")
reader := bufio.NewReader(os.Stdin)
input, err := reader.ReadString('n')
if err != nil {
log.Fatal(err)
}
fmt.Println(input)
}
Вот еще один пример:
// сообщает размер файла my1.txt
package main
import (
"fmt"
"log"
"os"
)
func main() {
fileInfo, err := os.Stat("my1.txt")
if err != nil {
log.Fatal(err)
}
fmt.Println(fileInfo.Size())
}
27. Избегайте замещения имен
Пример кода:
fmt.Print("Enter a grade: ")
reader := bufio.NewReader(os.Stdin)
input, err := reader.ReadString('n')
if err != nil {
log.Fatal(err)
}
Ранее говорили, что стараетесь избегать сокращений.
А здесь переменной присваивается имя err вместо error!
Называть переменную error не рекомендуется, потому что
это приведет к замещению типа с именем error
Объявляя переменную, проследите за тем, чтобы ее имя не совпадало с именами существующих функций, пакетов, типов или других переменных.
Если такое имя уже существует во внешней области видимости (вскоре мы поговорим об областях видимости),
ваша переменная заместит его, то есть будет перехватывать все обращения к нему.
И часто это нежелательно.
В следующем фрагменте объявляется переменная с именем int, которая замещает имя типа, переменная с именем append,
которая замещает имя встроенной функции (функция append будет представлена в главе 6), а также переменная с именем fmt, которая замещает имя импортированного пакета.
Эти имена создают путаницу, но сами по себе не порождают ошибок...
Пример ошибок в коде
package main
import "fmt"
func main() {
var int int = 12 //Переменная с именем «int» замещает имя встроенного типа «int»!
var append string = "minutes of bonus footage" //Переменная с именем «append» замещает имя встроенной функции «append»!
var fmt string = "DVD" //Переменная с именем «fmt» замещает имя импортированного пакета «fmt»!
var count int //int» теперь относится к переменной, объявленной выше, а не к числовому типу
var languages = append([]string{}, "Español") //Имя «append» теперь обозначает переменную, а не функцию!
fmt.Println(int, append, "on", fmt, languages) //Имя «fmt» теперь обозначает переменную, а не пакет
}
# command-line-arguments
./06_varerrorcode.go:3:8: imported and not used: "fmt"
./06_varerrorcode.go:9:6: int is not a type
./06_varerrorcode.go:10:24: cannot call non-function append (type string), declared at ./06_varerrorcode.go:7:6
./06_varerrorcode.go:11:5: fmt.Println undefined (type string has no field or method Println)
Чтобы не путаться самому и не путать коллег, старайтесь по возможности избегать замещения имен.
В данном случае проблема решается простым выбором неконфликтующих имен для переменных:
Исправили код:
package main
import "fmt"
func main() {
var count int = 12
var suffix string = "minutes of bonus footage"
var format string = "DVD"
var languages = append([]string{}, "Español")
fmt.Println(count, suffix, "on", format, languages)
}
Вот почему при объявлении переменных, предназначенных для хранения ошибок, мы присваивали им имя err вместо error,
мы хотели предотвратить замещение имени типа ошибки именем переменной.
package main
import "fmt"
fmt.Print("Enter a grade: ")
reader := bufio.NewReader(os.Stdin)
input, err := reader.ReadString('n') // err а не error!
if err != nil {
log.Fatal(err)
}
Если вы все же назовете свою переменную error, возможно, ваш код будет работать.
По крайней мере до того момента, как вы забудете, что имя типа ошибки было замещено, попробуете воспользоваться типом и получите вместо него переменную.
Лучше не рисковать; используйте имя err для своих переменных со значениями ошибок.
28. Преобразование строк в числа
Условные команды также могут быть использованы для проверки введенного значения.
Давайте воспользуемся командой if/else для определения того, прошел ли пользователь экзамен или нет.
Если введенный процент правильных ответов равен 60 и выше, переменной status присваивается строка "passing".
В противном случае переменной будет присвоена строка "failing".
Пример кода:
package main
import "fmt"
func main() {
fmt.Print("Enter a grade:")
reader := bufio.NewReader(os.Stdin)
input, err := reader.ReadString('n')
if err != nil {
log.Fatal(err)
}
if input >= 60 {
status := "passing"
} else {
status := "failing"
}
}
!!! Код не заработает в текущем варианте этой программы выдается ошибка компиляции.
Дело в том, что ввод с клавиатуры читается как строка.
Go может сравнивать числа только с другими числами, сравнить число со строкой не удастся.
А прямого преобразования типа из строки в число не существует:
float64("2.6") - Ошибка cannot convert "2.6" (type string) to type float64
Мы должны решить две задачи:
1. В конце строки input находится символ новой строки, появившийся в результате нажатия клавиши Enter в процессе ввода.
Его необходимо удалить.
2. Остальные символы строки необходимо преобразовать в число с плавающей точкой.
Удалить символ новой строки из конца входного текста несложно.
Пакет strings содержит функцию TrimSpace, которая удаляет все символы-пропуски (символы новой строки, табуляции и обычные пробелы) в начале и в конце строки.
s := "t formerly surrounded by space n"
fmt.Println(strings.TrimSpace(s))
Таким образом, чтобы убрать символ новой строки из входной строки, следует передать ее TrimSpace,
а затем снова присвоить возвращенное значение переменной input.
input = strings.TrimSpace(input)
После этого в строке input должно остаться только число, введенное пользователем.
Мы воспользуемся функцией ParseFloat из пакета strconv, чтобы преобразовать его в значение float64.
В аргументах передается преобразуемая строка
|
grade, err := strconv.ParseFloat(input, 64)
| | |
| Возможная ошибка Количество битов точности для результата
Возвращаемые значения - flat64
Функции ParseFloat передается строка, которую необходимо преобразовать в число, а также количество битов точности для результата.
Поскольку строка преобразуется в значение float64, мы передаем число 64.
(Кроме float64, в Go также поддерживается менее точный тип float32, однако им лучше не пользоваться, если только у вас нет на это веских причин.)
Функция ParseFloat преобразует число в строку и возвращает его в форме float64.
Как и ReadString, она также имеет второе возвращаемое значение — значение ошибки.
Оно должно быть равно nil, если только в ходе преобразования строки не возникли какие-то проблемы.
(Например, переданная строка не может быть преобразована в число.
Да и какой может быть числовой эквивалент у строки "hello"...)
Оффтоп:
Все эти «биты точности» сейчас не так уж важны.
По сути это просто размер компьютерной памяти, используемой для хранения числа с плавающей точкой.
Если вы уверены в том, что вам нужно число float64, всегда передавайте 64 во втором аргументе ParseFloat, и все будет хорошо.
package main
import (
"bufio"
"log"
"os"
"strconv"
"strings"
"fmt"
)
func main() {
fmt.Print("Enter a grage: ")
reader := bufio.NewReader(os.Stdin)
input, err := reader.ReadString('n')
if err != nil {
log.Fatal(err)
}
input = strings.TrimSpace(input)
grade, err := strconv.ParseFloat(input, 64)
if err != nil {
log.Fatal(err)
}
if grade >= 60 {
status := "passing"
} else {
status := "failing"
}
fmt.Println("A grade of", grade, "is", status)
}
Сначала нужные пакеты включаются в директиву import.
Мы добавляем код удаления символа новой строки из входного текста, после чего передаем ввод функции ParseFloat
и сохраняем полученное значение float64 в новой переменной grade.
Как и в случае с ReadString, мы проверяем, возвращает ли ParseFloat значение ошибки.
В этом случае программа сообщает об ошибке и аварийно завершается.
Наконец, мы обновляем условную команду, чтобы она проверяла число в grade, а не строку в input.
На этом все ошибки, происходящие от сравнения строки с числом, должны быть исправлены.
При запуске обновленной программы мы уже не получаем сообщение о несовпадении типов string и int.
Но тут есть и еще ошибки :)
Код Go делится на блоки (сегменты).
Блоки обычно заключаются в фигурные скобки ({}) и могут существовать как на уровне файлов с исходным кодом,
так и на уровне пакетов.
Блоки могут вкладываться друг в друга.
Тела функций и условных команд тоже являются блоками.
Понимание этого — ключ к решению нашей проблемы с переменной status
29. Блоки и область видимости переменной
Каждая объявленная переменная обладает областью видимости: частью кода, в которой она «видна».
К объявленной переменной можно обращаться в любой точке ее области видимости,
однако при попытке обратиться к ней за пределами этой области видимости вы получите сообщение об ошибке.
Область видимости переменной состоит из блока, в котором она была объявлена, и всех блоков, вложенных в этот блок.
Пример кода:
package main
import "fmt"
var packageVar = "package"
func main() {
var functionVar = "function"
if true {
var conditionalVar = "conditional"
fmt.Println(packageVar) //все еще в области видимости
fmt.Println(functionVar) //все еще в области видимости
fmt.Println(conditionalVar) //все еще в области видимости _ область видимости conditionalVar
} //Область видимости conditionalVar
fmt.Println(packageVar) //Все еще в области видимости
fmt.Println(functionVar) //Все еще в области видимости
fmt.Println(conditionalVar) //не определенно не в области видимости
}//Область видимости functionVar)
Ошибка:
# command-line-arguments
./02_x123.go:17:14: undefined: conditionalVar
Области видимости переменных в приведенном выше коде:
- Областью видимости packageVar является весь пакет main.
К packageVarможно обращаться в любой точке любой функции, определенной в пакете.
- Областью видимости functionVar является вся функция, в которой объявлена переменная, включая блок if, вложенный в эту функцию.
- Область видимости conditionalVar ограничивается блоком if.
При попытке обратиться к conditionalVar после закрывающей фигурной скобки } блока if вы получите сообщение об ошибке,
в котором говорится, что переменная conditionalVar не определена!
30. Блоки и области видимости переменной:
Пример кода:
package main
import (
"bufio"
"log"
"os"
"strconv"
"strings"
"fmt"
)
func main() {
fmt.Print("Enter a grage: ")
reader := bufio.NewReader(os.Stdin)
input, err := reader.ReadString('n')
if err != nil {
log.Fatal(err)
}
input = strings.TrimSpace(input)
grade, err := strconv.ParseFloat(input, 64)
if err != nil {
log.Fatal(err)
}
if grade >= 60 {
status := "passing"
} else {
status := "failing"
}
fmt.Println("A grade of", grade, "is", status)
}
Ошибка:
undefined: status
Рассмотрим проблему:
func main() { // Начало блока фунции
// Omitting code up here...
if grade >= 60 {
status := "passing" //Блок if
} else {
status := "failing" // Блок else
}
fmt.Println("A grade of", grade, "is", status) // В этой области видимости переменная "status" НЕ ОПРЕДЕЛЕНА!
//Конец блока функции
Проблема решается перемещением объявления переменной status из блоков условных команд в блок функции.
После этого переменная status будет находиться в области видимости как во вложенных условных блоках, так и в конце блока функции.
Решение:
Пример кода:
package main
import (
"bufio"
"log"
"os"
"strconv"
"strings"
"fmt"
)
func main() { //Функция «main» вызывается при запуске программы.
fmt.Print("Enter a grage: ") //Запрашиваем у пользователя значение.
reader := bufio.NewReader(os.Stdin) //Создаем bufio.Reader для чтения ввода с клавиатуры.
input, err := reader.ReadString('n') //Читает данные, вводимые пользователем до нажатия клавиши Enter
// Если произошла ошибка, вывести сообщение и прервать работу программы.
if err != nil {
log.Fatal(err)
}
input = strings.TrimSpace(input) //Удалить символ новой строки из введенных данных.
grade, err := strconv.ParseFloat(input, 64) //Преобразовать введенную строку в значение float64 (число).
//Если произошла ошибка, вывести сообщение и прервать выполнение программы.
if err != nil {
log.Fatal(err)
}
var status string //Переменная «status» объявляется здесь, чтобы она находилась в области видимости в границах функции.
//Если значение grade равно 60 и более, переменной status присваивается строка «passing».
В противном случае переменной присваивается строка «failing».
if grade >= 60 {
status = "passing" // так как перемену мы задали выше тут мы уже используем присвоение
} else {
status = "failing" // так как перемену мы задали выше тут мы уже используем присвоение
}
fmt.Println("A grade of", grade, "is", status)
} | |
| и результат сдачи экзамена
Выводим введенное значение...
Вы можете запускать программу сколько угодно раз.
Введите значение меньше 60, и получите сообщение о том, что экзамен не сдан.
Введите значение больше 60, и программа сообщит, что экзамен сдан успешно.
Кажется, все работает!
31. Только одна переменная в коротком объявлении должна быть новой?
Пример:
input, err := reader.ReadString('n')
grade, err := strconv.ParseFloat(input, 64)
В этом коде есть странность.
До этого говорили, что переменную нельзя объявить дважды.
Тем не менее переменная err встречается в двух разных коротких объявлениях!
Действительно, если дважды объявить одно имя переменной в одной области видимости, компилятор выдаст сообщение об ошибке:
a := 1
a := 2
Ошибка компиляции:
# command-line-arguments
./05_x1.go:7:11: no new variables on left side of :=
Но если хотя бы одно имя переменной в коротком объявлении является новым, такая запись допустима.
Новые имена переменных интерпретируются как объявление, а существующие — как присваивание.
У этого специального подхода есть причина:
многие функции Go возвращают несколько значений.
Было бы неприятно объявлять отдельно все переменные только потому, что вы захотели повторно использовать одну из них.
Вместо этого Go позволяет использовать короткие объявления переменных, даже если для одной из переменных в действительности выполняется присваивание
Пример:
Вариант с отдельными объявлениями всех переменных работает, но, к счастью, поступать так не обязательно...
var a, b float64
var err error
a, err = strconv.ParseFloat("1.23", 64)
b, err = strconv.ParseFloat("4.56", 64)
Можно просто воспользоваться синтаксисом короткого объявления переменных
a, err := strconv.ParseFloat("1.23", 64) - Объявляем «a» и «err».
b, err := strconv.ParseFloat("4.56", 64) - Объявляем «b» и присваиваем «err».
fmt.Println(a, b, err)
32. Генерация случайного числа / пакет ("math/rand")
Пакет math/rand содержит функцию Intn, которая сгенерирует случайное число за нас, поэтому в программу следует импортировать math/rand.
После этого можно будет вызвать функцию rand.Intn для генерирования случайного числа
Пример кода:
package main
import (
"fmt"
"math/rand"
)
func main() {
target := rand.Intn(100) + 1
fmt.Println(target)
}
Передайте число функции rand.Intn, и функция вернет случайное число в диапазоне от 0 до переданного числа.
Другими словами, если передать аргумент 100, будет получено случайное число в диапазоне 0–99.
Так как нам требуется число в диапазоне 1–100, остается прибавить 1 к полученному случайному значению.
Результат сохраняется в переменной target.
Пока мы ограничимся простым выводом переменной target.
Попытавшись запустить программу в таком виде, вы получите случайное число.
Однако вы будете получать одно и то же случайное число раз за разом!
Чтобы получать разные случайные числа, необходимо передать значение функции rand.Seed.
Тем самым вы «инициализируйте» генератор случайных чисел, то есть предоставляете значение, которое будет использоваться для генерирования других случайных чисел.
Но если передавать одно и то же значение инициализации, то и случайные значения будут теми же и мы снова вернемся к тому, с чего начинали.
Ранее было показано, что функция time.Now выдает значение Time, представляющее текущую дату и время.
Его можно использовать для того, чтобы получать разное значение инициализации при каждом запуске программы.
Пример кода:
package main
import (
"fmt"
"math/rand"
"time"
)
func main() {
seconds := time.Now().Unix()
rand.Seed(seconds)
target := rand.Intn(100) + 1
fmt.Println(target)
}
Функция rand.Seed ожидает получить целое число, поэтому передать ей значение Time напрямую не удастся.
Вместо этого для Time следует вызвать метод Unix, который преобразует его в целое число.
(А конкретно значение будет преобразовано в формат времени Unix — целое количество секунд, прошедших с 1 января 1970 года. Впрочем, запоминать это не нужно.)
Это число передается rand.Seed.
33. Путь импортирования пакета
Пакет math/rand содержит функцию Intn, которая сгенерирует случайное число за нас, поэтому в программу следует импортировать math/rand.
После этого можно будет вызвать функцию rand.Intn для генерирования случайного числа
Упоминая math/rand, мы имеем в виду путь импортирования пакета, а не его имя.
Путь импортирования — всего лишь уникальная строка, которая идентифицирует пакет и используется в директиве import.
После того как пакет будет импортирован, к нему можно обращаться по имени пакета.
Для всех пакетов, которые использовались до сих пор, путь импортирования совпадал с именем пакета.
Несколько примеров:
Путь импортирования Имя пакета
"fmt" fmt
"log" log
"strings" strings
Однако путь импортирования и имя пакета могут различаться.
Многие пакеты Go классифицируются по категориям — например, «сжатие» или «комплексные вычисления».
По этой причине они часто группируются
по префиксам пути импортирования (например, "archive/" или "math/"). (Их можно рассматривать как аналоги путей каталогов на жестком диске.)
Несколько примеров:
Путь импортирования Имя пакета
"archive" archive
"archive/tar" tar
"archive/zip" zip
"math" math
"math/cmplx" cmplx
"math/rand" rand
Язык Go не требует, чтобы имя пакета было как-то связано с путем импортирования.
Но по соглашению последний (или единственный) сегмент пути импортирования также используется в качестве имени пакета.
Таким образом, для пути импортирования "archive" именем пакета также будет archive, а для пути импортирования "archive/zip" будет использоваться имя пакета zip.
Именно по этой причине в директиве import используется путь "math/rand", а в функции main имя пакета — rand.
34. Циклы / Цикл for
Пример кода:
package main
import "fmt"
func main() {
for x := 4; x <= 6; x++ {
fmt.Println("x is now", x)
}
}
Разберем:
for x := 4; x <= 6; x++ {
fmt.Println("x is now", x)
}
for - ключевое слово
x:=4 - команда инициализации
x < 6 - Условное выражение
x++ - Операция приращения
{ - начало блока цикла
}конец блока цикла
fmt.Println("x is now", x) - тело блока цикла
Циклы всегда начинаются с ключевого слова for. В одной из стандартных разновидностей циклов за for следуют три сегмента кода, которые управляют циклом:
- Команда инициализации, обычно используемая для инициализации переменной.
- Условное выражение, которое определяет, когда следует прервать выполнение цикла.
- Оператор приращения, который выполняется после каждой итерации цикла.
Команда инициализации часто используется для инициализации переменной;
условное выражение обеспечивает выполнение цикла до того, как переменная достигнет определенного значения, и оператор приращения обновляет значение этой переменной.
Например, в приведенном фрагменте переменная t инициализируется значением 3, условие обеспечивает выполнение цикла, пока t > 0,
а оператор приращения уменьшает t на 1 при каждом выполнении цикла.
В конечном итоге t уменьшается до 0 и цикл завершается.
package main
import "fmt"
func main() {
for t := 3; t > 0; t-- {
fmt.Println(t)
}
fmt.Println("Blastoff!")
}
Операторы ++ и -- часто встречаются в командах приращения циклов.
++ увеличивает значение переменной на 1, а -- уменьшает его на 1.
Примеры кода:
x := 0
x++
fmt.Println(x)
x++
fmt.Println(x)
x--
fmt.Println(x)
for x := 1; x <= 3; x++ {
fmt.Println(x)
}
for x := 3; x >= 1; x-- {
fmt.Println(x)
}
В языке Go также поддерживаются операторы присваивания += и -=.
Они получают значение в переменной, добавляют или вычитают другое значение, а затем присваивают результат той же переменной.
Примеры кода:
x := 0
x += 2
fmt.Println(x)
x += 5
fmt.Println(x)
x -= 3
fmt.Println(x)
Операторы += и -= также могут использоваться в циклах для изменения переменной на величину, отличную от 1.
for x := 1; x <= 5; x += 2 {
fmt.Println(x)
}
for x := 15; x >= 5; x -= 5 {
fmt.Println(x)
}
Когда цикл завершается, выполнение программы продолжится с команды, следующей за блоком цикла.
При этом цикл продолжает выполняться, пока условное выражение остается истинным.
Этот факт может иметь нежелательные последствия;
ниже приведены примеры циклов, которые выполняются бесконечно или не выполняются ни одного раза:
бесконечный цикл:
for x := 1; true; x++ {
fmt.Println(x)
}
Цикл не выполнится никогда:
for x := 1; false; x++ {
fmt.Println(x)
}
Будьте осторожны!
Цикл может выполняться бесконечно.
В этом случае ваша программа никогда не остановится сама.
Если это случится, в активном окне терминала нажмите клавишу Control одновременно с клавишей C, чтобы прервать выполнение программы.
Операторы инициализации и приращения необязательны.
При желании операторы инициализации и приращения в заголовке цикла for можно опустить,
оставив только условное выражение (хотя вы должны проследить за тем, чтобы условие в какой-то момент становилось ложным, иначе в программе возникнет бесконечный цикл).
x := 1
for x <= 3 {
fmt.Println(x)
x++
}
x := 3
for x >= 1 {
fmt.Println(x)
x--
}
35. Циклы и области видимости
Как и в случае с условными командами, область видимости любых переменных, объявленных в блоке цикла,
ограничивается этим блоком (хотя команда инициализации, условное выражение и оператор приращения также могут считаться частью этой области видимости).
Пример:
for x := 1; x <= 3; x++ {
y := x + 1
fmt.Println(y) //Остается в области видимости...
}
fmt.Println(y) //Ошибка: вне области видимости! (undefined: y)
Ошибка:
# command-line-arguments
./13_loop.go:11:14: undefined: y
Пример:
for x := 1; x <= 3; x++ {
fmt.Println(x) //Остается в области видимости...
}
fmt.Println(x) //Ошибка: вне области видимости! (undefined: x)
Ошибка:
# command-line-arguments
./15_loop.go:9:14: undefined: x
Как и в случае с условными командами, любые переменные, объявленные до начала цикла,
находятся в области видимости в заголовке и блоке цикла и остаются в области видимости после выхода из цикла.
var x int //Объявляется за пределами цикла
for x = 1; x <= 3; x++ { //Объявлять x здесь не нужно, просто присвойте значение
fmt.Println(x) //Остается в области видимости.
}
fmt.Println(x) //Остается в области видимости.
36. Сломай и изучи!
Пример кода:
package main
import "fmt"
func main() {
for x := 1; x <= 3; x++ {
fmt.Println(x)
}
}
0. Добавить круглые скобки после ключевого слова for
for (x := 1; x <= 3; x++)
Ошибка:
# command-line-arguments
./17_dz.go:7:9: syntax error: unexpected :=, expecting )
Что:
Другие языки требуют, чтобы управляющая часть цикла for заключалась в круглые скобки.
Однако язык Go не только этого не требует, но и запрещает.
1. Удалить : из команды инициализации x = 1
Ошибка:
# command-line-arguments
./17_dz.go:9:6: undefined: x
./17_dz.go:10:15: undefined: x
Что:
Если только вы не присваиваете значение переменной, уже объявленной во внешней области видимости (а это бывает довольно редко),
команда инициализации должна быть объявлением, а не присваиванием.
2. Удалить = из условного выражения x < 3
Выражение x<3 становится ложным , когда значение x становится равным 3 (тогда как выражение x<=3 все еще остается истинным).
Таким образом, цикл будет вести отсчет только до 2.
3. Использовать противоположный оператор сравнения в условном выражении x >= 3
Так как условие будет ложным уже в самом начале цикла (x инициализируется 1, что меньше 3), цикл не будет выполнен ни одного раза
4. Заменить оператор приращения x++ на x--
Переменная x начинает отсчет с 1 (1, 0, -1, -2 и т. д.). Так как она никогда не станет больше 3, цикл будет выполняться бесконечно
5. Переместить команду fmt.Println(x) за пределы блока цикла
Переменные, объявленные в команде инициализации или в блоке цикла, остаются в области видимости только в пределах блока цикла
# command-line-arguments
./17_dz.go:15:15: undefined: x
37. Пропуск частей цикла командами continue и break
В Go предусмотрены два ключевых слова для управления циклом.
Первое — continue — осуществляет немедленный переход к следующей итерации цикла;
при этом дальнейший код текущей итерации в блоке цикла пропускается.
for x := 1; x <= 3; x++ {
fmt.Println("before continue")
continue
fmt.Println("after continue")
}
В приведенном выше примере строка "after continue" никогда не выводится,
потому что ключевое слово continue всегда выполняет переход к началу цикла — до того, как отработает второй вызов Println.
Второе ключевое слово break приводит к немедленному выходу из цикла. Дальнейший код в блоке цикла не отрабатывается, другие итерации цикла не выполняются.
Управление передается первой команде, следующей за циклом.
for x := 1; x <= 3; x++ {
fmt.Println("before break")
break
fmt.Println("after break")
}
fmt.Println("after loop")
Здесь при первой итерации цикла выводится сообщение "before break", после чего команда break немедленно прерывает цикл;
сообщение "after break" не выводится, и цикл не выполняется повторно (хотя без break он бы выполнился еще два раза).
Управление передается команде, следующей за циклом.
38. Комментарии (guess)
//guess - игра, в которой игрок должен отгадать случайное число.
package main
import (
"bufio" // пакет отвечает за input keyboard
"fmt" // вывод в консоль
"log" // работает с ошибками err
"math/rand" // отвечает за генерацию чисел
"os" // использование возможностей ОС
"strconv" // работа со строками, преобразование
"strings" // работа со строками
"time" // работает со временем, используется
)
func main() {
seconds := time.Now().Unix() //Получает текущую дату и время в виде целого числа.
rand.Seed(seconds) // Инициализируем генератор случайных чисел.
target := rand.Intn(100) + 1 // Генерируем целое число 1 от 100
fmt.Println("I've chosen a random number between 1 and 100.")
fmt.Println("Can you guess it?")
reader := bufio.NewReader(os.Stdin) // Создаем bufio.Reader для чтения ввода с клавиатуры.
success := false // Настроить программу, чтобы по умолчанию выводилось сообщение о проигрыше.
for guesses := 0; guesses < 10; guesses++ {
fmt.Println("You have", 10-guesses, "guesses left.")
fmt.Print("Make a guess: ") // Запрашиваем число.
input, err := reader.ReadString('n') // Прочитать данные, введенные пользователем до нажатия Enter.
if err != nil {
// Если произошла ошибка программа выводит сообщение и завершается
log.Fatal(err)
}
input = strings.TrimSpace(input) // Удаляем символ новой строки.
guess, err := strconv.Atoi(input) // Введенная строка преобразуется в целое число
if err != nil {
// Если произошла ошибка программа выводит сообщение и завершается
log.Fatal(err)
}
if guess < target {
// если введенное значение меньше загаданного, сообщить об этом.
fmt.Println("Oops. Your guess was LOW")
} else if guess > target {
// Если введено сообщение больше загаданного, сообщить об этом
fmt.Println("Oops.Your guss was HIGH")
} else {
// В противном случае введенное значение должно быть правильным...
success = true //Предотвращает вывод сообщения о проигрыше.
fmt.Println("Good job! You guessed it")
break //Выход из цикла
}
}
if !success {
// Если переменная «success» равна false, сообщить игроку загаданное число.
fmt.Println("Sorry, you diddn't guess my number. It was:", target)
}
}
39. Проведем промежуточные итоги
0. Метод — разновидность функций, связываемых со значениями конкретного типа.
1. Go интерпретирует все символы от // до конца строки как комментарий и игнорирует их.
2. Многострочные комментарии начинаются с /* и завершаются */.
Все символы между этими маркерами, включая символы новой строки, игнорируются.
3. Традиционно в начало любой программы включается комментарий, который объясняет, что делает программа.
4. В отличие от большинства языков программирования, Go допускает множественные возвращаемые значения из вызова функции или метода.
5. Одно из стандартных применений множественных возвращаемых значений — возвращение основного результата функции и второго значения,
которое сообщает, произошла ли ошибка при вызове.
6. Чтобы проигнорировать значение без реального использования в программе, воспользуйтесь пустым идентификатором _.
Пустой идентификатор может использоваться вместо любой переменной в любой команде присваивания.
7. Постарайтесь не присваивать переменным имена, совпадающие с именами типов, функций или пакетов;
это приведет к замещению (переопределению) элемента с тем же именем
8. Функции, условные команды и циклы содержат блоки кода, заключенные в фигурные скобки {}.
9. Файлы и пакеты также образуют блоки, хотя содержащийся в них код и не заключается в фигурные скобки {}.
10. Область видимости переменной ограничивается блоком, в котором она определяется, а также всеми блоками, вложенными в этот блок.
11. Кроме имени, пакет может иметь путь импортирования, который должен указываться при импортировании.
12. Ключевое слово continue осуществляет переход к следующей итерации цикла.
13. Ключевое слово break полностью прерывает выполнение цикла.
14. Условные команды
Условные команды обеспечивают выполнение блока кода только в случае истинности заданного условия.
Вычисляется результат выражения, и если его результат равен true, то выполняется тело условного блока.
Go поддерживает множественное ветвление в условиях.
Такие команды записываются в форме if...else if...else.
15. Циклы
Циклы предназначены для многократного выполнения блока кода.
Одна из распространенных разновидностей циклов начинается
с ключевого слова «for», за которым следует команда инициализации переменной;
условное выражение, которое определяет, когда цикл должен прерваться;
и оператор приращения, выполняемый после каждой итерации цикла.
40. Функции вступление
Допустим есть код:
/*Допустим, вы хотите вычислить, сколько
краски потребуется для покрытия нескольких стен.
Производитель указывает, что одного литра краски хватает на 10 квадратных метров.
Следовательно, для определения количества литров необходимо вычислить площадь каждой стены,
умножив ее ширину (в метрах) на высоту, а затем разделить результат на 10.*/
package main
import "fmt"
func main() {
var width, height, area float64
//Вычислить расход краски для первой стены.
width = 4.2
height = 3.0
area = width * height //Вычисляем площадь стены.
fmt.Println(area/10.0, "liters needed") //Вычисляем, сколько краски понадобится для этой площади.
//Сделать то же для этой площади. самое для второй стены.
width = 5.2
height = 3.5
area = width * height
fmt.Println(area/10.0, "liters needed") //Вычисляем, сколько краски понадобится для этой площади.
}
Такое решение работает, но у него есть пара недостатков:
0. Похоже, произведение вычисляется с небольшой погрешностью, поэтому выводимые значения выглядят немного странно.
Хватило бы пары цифр в дробной части.
1. В этой версии присутствует большое количество повторяющегося кода.
Если мы добавим новые стены, все станет еще хуже.
41. Форматирование вывода функциями Printf и Sprintf
Числа с плавающей точкой в языке Go хранятся с высокой степенью точности.
Если вам потребуется вывести такое число, результат может быть громоздким и неудобным:
fmt.Println("About one-third:", 1.0/3.0)
Для решения подобных проблем форматирования в пакете fmt имеется функция
Printf (сокращение от «print, with formatting», то есть «вывод с форматированием»).
Функция получает строку и вставляет в нее одно или несколько значений, отформатированных заданным способом.
После этого функция выводит полученную строку.
fmt.Printf("About one-third: %0.2fn", 1.0/3.0)
Функция Sprintf (также из пакета fmt) в целом похожа на Printf, но она возвращает отформатированную строку, а не выводит ее.
resultString := fmt.Sprintf("About one-third: %0.2fn", 1.0/3.0)
fmt.Printf(resultString)
42. Глаголы форматирования
В первом аргументе Printf передается строка, которая будет использоваться для форматирования вывода.
Большая часть вывода форматируется так, как он выглядит в строке.
Однако знаки процента (%) рассматриваются как начало глагола форматирования — части строки, которая будет заменена значением в определенном формате.
Остальные аргументы определяют значения, которые будут форматироваться с этими глаголами.
Глагол Глагол Значение Значение
| | | |
fmt.Printf("The %s cost %d cents each.n", "gumballs", 23)
fmt.Printf("That will be $%f please.n", 0.23 * 5)
| --------
Глагол |
Значение
Глагол Вывод
%f Число с плавающей точкой
%d Десятичное целое число
%s Строка
%t Логическое значение (true или false)
%v Произвольное значение (подходящий формат выбирается на основании типа передаваемого значения)
%#v Произвольное значение, отформатированное в том виде, в котором оно отображается в коде Go
%T Тип переданного значения (int, string и т. п.)
%% Знак процента (литерал)
fmt.Printf("A float: %fn", 3.1415)
fmt.Printf("An integer: %dn", 15)
fmt.Printf("A string: %sn", "hello")
fmt.Printf("A boolean: %tn", false)
fmt.Printf("Values: %v %v %vn", 1.2, "t", true)
fmt.Printf("Values: %#v %#v %#vn", 1.2, "t", true)
fmt.Printf("Types: %T %T %Tn", 1.2, "t", true)
fmt.Printf("Percent sign: %%n")
Обратите внимание: в конец каждой форматной строки включается символ новой строки в виде служебной последовательности n.
Дело в том, что в отличие от Println, Printf не добавляет символ новой строки автоматически.
Особого внимания заслуживает глагол формата %#v.
Так как он выводит значения в том виде, в котором они отображаются в коде Go,
%#v позволяет выводить значения, которые обычно остаются скрытыми в выводе.
Например, в следующем примере %#v показывает пустую строку,
символ табуляции и символ новой строки — все эти символы остаются невидимыми при выводе с %v.
%v выводит все значения...
…но только с %#v вы можете фактически их увидеть!
fmt.Printf("%v %v %v", "", "t", "n")
fmt.Printf("%#v %#v %#v", "", "t", "n")
Форматирование значений ширины
Глагол форматирования %f предназначен для чисел с плавающей точкой.
Используем его для форматирования количества краски.
fmt.Printf("%f liters neededn", 1.8199999999999998)
Предположим, вы хотите отформатировать данные в форме текстовой таблицы.
Необходимо позаботиться о том, чтобы отформатированное значение занимало минимальное количество столбцов, а столбцы правильно выравнивались.
Минимальная ширина может задаваться после знака процента в глаголе форматирования.
Если аргумент, соответствующий этому глаголу, короче минимальной длины, значение дополняется пробелами до достижения минимальной ширины.
Пример кода таблицы:
fmt.Printf("%12s | %sn", "Product", "Cost in Cents")
fmt.Println("-----------------------------")
fmt.Printf("%12s | %2dn", "Stamps", 50)
fmt.Printf("%12s | %2dn", "Paper Clips", 5)
fmt.Printf("%12s | %2dn", "Tape", 99)
Форматирование с дробными значениями ширины
Минимальная ширина всего числа.
| Ширина дробной части.
| |
%5.3f
| |
| Тип глагола форматирования.
Начало спецификатора форматирования.
Минимальная ширина всего числа включает дробную часть и точку-разделитель.
Если она указана, то более короткие числа будут дополняться пробелами в начале до достижения указанной ширины.
Если она не указана, то пробелы не добавляются.
Ширина после точки определяет количество цифр в дробной части.
Если выводимое число имеет больше разрядов, оно округляется (в большую или меньшую сторону) до заданного количества разрядов.
fmt.Printf("%%7.3f: %7.3fn", 12.3456)
fmt.Printf("%%7.2f: %7.2fn", 12.3456)
fmt.Printf("%%7.1f: %7.1fn", 12.3456)
fmt.Printf("%%.1f: %.1fn", 12.3456)
fmt.Printf("%%.2f: %.2fn", 12.3456)
Последний формат "%.2f" позволяет взять число с плавающей точкой с произвольной точностью
и округлить его до двух цифр в дробной части. (Также при этом число не дополняется лишними пробелами.)
43. Функции
Объявление функций
ключевое слово
| Имя функции
| |
func sayHi() { - начало блока функции
fmt.Println("Hi!") - тело блока функции
}
|
Конец блока функции.
После того как функция будет объявлена, вы сможете вызывать ее в пакете — для этого достаточно указать ее имя и пару круглых скобок.
При этом будет выполнен код функции.
Обратите внимание: при вызове sayHi перед именем функции не ставится имя пакета и точка.
При вызове функции, определенной в текущем пакете, указывать имя пакета не нужно.
(А вызов main.sayHi() приведет к ошибке компиляции.)
Пример использования:
package main
import "fmt"
func sayHi() {
fmt.Println("Hi!")
}
func main() {
for x := 4; x > 1; x-- {
sayHi()
}
}
Имена функций подчиняются тем же правилам, что и имена переменных:
1.Имя должно начинаться с буквы, за которой следует произвольное количество букв и цифр.
(При нарушении этого правила выдается ошибка компиляции.)
2. Функция, имя которой начинается с буквы верхнего регистра, экспортируется и может использоваться вне текущего пакета.
Если функция должна использоваться только внутри текущего пакета, начните ее имя с буквы нижнего регистра.
3. Имена, состоящие из нескольких слов, должны записываться в верблюжьем регистре.
Допускается:
double
addPart - Если имя состоит из нескольких слов, используется верблюжий регистр.
Publish - Если функция должна использоваться другими пакетами, ее имя начинается с буквы верхнего регистра.
Недопустимо:
2times - Имя не может начинаться с цифры.
addpart - Нарушает соглашения; следует использовать верблюжий регистр
posts.publish - Недопустимо; к функции нельзя обращаться из другого пакета, если ее имя не начинается с буквы верхнего регистра.
44. Объявление параметров функции
Если вы хотите, чтобы при вызове ваших функций передавались аргументы, необходимо объявить один или несколько параметров.
Параметром называется переменная, локальная по отношению к функции, значение которой задается при вызове функции.
Имя параметра
| тип Имя тип
| | | |
func repeatLine(line string, times int) {
for i := 0; i < times; i++ {
fmt.Println(line)
}
Параметр — переменная, локальная по отношению к функции, значение которой задается при вызове функции.
В объявлении функций в круглых скобках можно объявить один или несколько параметров, разделенных запятыми.
Как и с любыми другими переменными, для каждого объявляемого параметра должно быть указано имя, за которым следует тип (float64, bool и т. д.).
Если функция имеет определенные параметры, нужно будет передать соответствующий набор аргументов при ее вызове.
Когда функция запускается, каждому параметру присваивается копия значения в соответствующем аргументе.
Эти значения параметров затем используются в функциональном блоке кода
Пример:
package main
import "fmt"
func repeatLine(line string, times int) {
for i := 0; i < times; i++ {
fmt.Println(line)
}
}
func main() {
repeatLine("helo", 10)
}
45. И вот мы научились использовать функции исправим код про краску:
package main
import "fmt"
func paintNeeded(width float64, height float64) {
area := width * height
fmt.Printf("%.2f liters neededn", area/10.0)
}
func main() {
paintNeeded(4.2, 3.0)
paintNeeded(5.2, 3.5)
paintNeeded(5.0, 3.3)
46. Функции и области видимости переменных
Функция paintNeeded объявляет переменную area в блоке функции:
func paintNeeded(width float64, height float64) {
area := width * height // Объявляем переменную area
fmt.Printf("%.2f liters neededn", area/10.0) // Обращение к переменной area
}
Как и в случае с блоками условных команд и циклов, переменные, объявленные в блоке функции,
остаются в области видимости только в границах блока функции.
Таким образом, если вы попытаетесь обратиться к переменной area вне функции paintNeeded, компилятор сообщит об ошибке:
func paintNeeded(width float64, height float64) {
area := width * height
fmt.Printf("%.2f liters neededn", area/10.0)
}
func main() {
paintNeeded(4.2, 3.0)
fmt.Println(area)
}
Ошибка:
# command-line-arguments
./11_func_err.go:11:14: undefined: area
Но как и в случае с блоками условных команд и циклов переменные, объявленные за пределами функции, будут находиться в области видимости внутри этого блока.
Это означает, что переменную можно объявить на уровне пакета и обращаться к ней из любой функции в этом пакете.
package main
import "fmt"
var metersPerLiter float64 // Если переменная объявляется на уровне пакета...
func paintNeeded(width, height float64) float64 {
area := width * height
return area / metersPerLiter //здесь она остается в области видимости.
}
func main() {
metersPerLiter = 10.0 //и здесь остается в области видимости.
fmt.Printf("%.2f", paintNeeded(4.2, 3.0))
}
47. Возвращаемые значения функций
Допустим, мы хотим вывести количество краски, необходимой для покрытия всех стен, которые мы собираемся покрасить.
Сделать это с текущей версией функции paintNeeded не удастся; она лишь выводит результат, а потом отбрасывает его!
func paintNeeded(width float64, height float64) {
area := width * height
fmt.Printf("%.2f liters neededn", area/10.0) //Выводит расход краски, но вычисленное значение будет потеряно!
}
Итак, пересмотрим функцию paintNeeded, чтобы она возвращала значение.
Тогда при ее вызове можно будет вывести полученное значение, провести дополнительные вычисления или сделать что-то еще.
Функция всегда возвращает значение конкретного типа (и только этого типа).
Чтобы объявить, что функция возвращает значение, добавьте тип возвращаемого значения после параметров в объявлении функции.
Затем добавьте в блок функции ключевое слово return, за которым следует возвращаемое значение.
Тип возвращаемого значения.
|
func double(number float64) float64 {
return number * 2
} | ----------
| |
| Возвращаемое значение.
|
Ключевое слово return.
После этого результат вызова функции можно присвоить переменной, передать другой функции или сделать что-то еще.
package main
import "fmt"
func double(number float64) float64 {
return number * 2
}
func main() {
dozen := double(6.0) //Возвращаемое значение присваивается переменной
fmt.Println(dozen)
fmt.Println(double(4.2)) //Возвращаемое значение передается другой функции.
}
При выполнении команды return функция немедленно возвращает управление, а следующий за ней код не выполняется.
Ее можно использовать в сочетании с командой if для выхода из функции в том случае,
если выполнение остального кода стало бессмысленным (из-за ошибки или другого условия).
func status(grade float64) string {
if grade < 60.0 {
return "failing" // Если экзамен провален, немедленно вернуть.
}
return "passing" // Выполняется только в том случае, если grade >= 60.
}
func main() {
fmt.Println(status(60.1))
fmt.Println(status(59))
}
Это означает, что при включении команды return, не являющейся частью блока if, какой-то код может не выполняться ни при каких условиях.
Такая ситуация почти наверняка свидетельствует об ошибке в коде, поэтому Go помогает обнаруживать подобные ситуации:
компилятор требует, чтобы любая функция с объявленным возвращаемым типом завершалась командой return.
Если функция завершается любой другой командой, это приведет к ошибке компиляции.
Пример:
func double(number float64) float64 {
return number * 2 //Функция всегда должна завершаться здесь...
fmt.Println(number * 2) //А эта строка никогда не должна выполняться!
}
Ошибка:
# command-line-arguments
./16_err_return.go:8:1: missing return at end of function
Ошибка компиляции произойдет и в том случае, если тип возвращаемого значения не соответствует объявленному возвращаемому типу.
func double(number float64) float64 { //Должно возвращаться число с плавающей точкой...
return int(number * 2) //...а возвращается целое число!
}
Ошибка:
# command-line-arguments
./17_err_return.go:4:12: cannot use int(number * 2) (type int) as type float64 in return argument
48. Использование возвращаемого значения в программе
Изменим функцию paintNeeded так, чтобы она возвращала необходимый объем.
Возвращаемое значение будет использоваться в функции main как для вывода расхода краски для текущей стены, так и для обновления переменной total,
в которой накапливается общий расход краски.
package main
import "fmt"
func paintNeeded(width float64, height float64) float64 { //объявляет, что paintNeeded возвращает число с плавающей точкой
area := width * height
return area / 10.0 //Функция возвращает расход краски вместо того, чтобы выводить его.
}
func main() {
var amount, total float64 //Объявляем переменные для хранения расхода краски для текущей сметы, а также для общего расхода по всем сменам.
amount = paintNeeded(4.2, 3.0) //Вызываем paintNeeded и сохраняем возвращаемое значение
fmt.Printf("%0.2f liters neededn", amount) //Выводим расход для первой сметы
total += amount //Прибавляем расход для текущий смены к total
amount = paintNeeded(5.2, 3.5)
fmt.Printf("%0.2f litersn", total)
total += amount
fmt.Printf("Total: %0.2f littersn", total) //Выводим общий расход по всем сменам
}
49. Ломаем:
Пример кода:
package main
import "fmt"
func paintNeeded(width float64, height float64) float64 {
area := width * height
return area / 10.0
func main() {
var amount, total float64
amount = paintNeeded(4.2, 3.0)
fmt.Printf("%0.2f liters neededn", amount)
total += amount
amount = paintNeeded(5.2, 3.5)
fmt.Printf("%0.2f litersn", total)
total += amount
fmt.Printf("Total: %0.2f littersn", total)
}
0. Удалить команду return:
func paintNeeded(width float64, height float64) float64 {
area := width * height
//return area / 10.0
}
Ошибка:
# command-line-arguments
./19_break.go:8:1: missing return at end of function
Если функция объявляет возвращаемый тип, Go требует, чтобы она содержала команду return
1. Добавить строку после команды return:
Добавить строку после команды return:
func paintNeeded(width float64, height float64) float64 {
area := width * height
return area / 10.0
fmt.Println(area / 10.0)
}
Ошибка:
# command-line-arguments
./19_break.go:10:1: missing return at end of function
Если функция объявляет возвращаемый тип, Go требует, чтобы ее последней командой была команда return
2. Удалить объявление возвращаемого типа:
func paintNeeded(width float64, height float64) /*float64*/ {
area := width * height
return area / 10.0
}
Ошибка:
# command-line-arguments
./19_break.go:9:2: too many arguments to return
have (float64)
want ()
./19_break.go:14:22: paintNeeded(4.2, 3) used as value
./19_break.go:17:22: paintNeeded(5.2, 3.5) used as value
Go не позволяет вернуть значение, тип которого не был объявлен
3. Изменить тип возвращаемого значения:
func paintNeeded(width float64, height float64) float64 {
area := width * height
return int(area / 10.0)
}
Ошибка:
# command-line-arguments
./19_break.go:11:12: cannot use int(area / 10) (type int) as type float64 in return argument
Go требует, чтобы тип возвращаемого значения соответствовал объявленному типу
50. Функции paintNeeded нужна обработка ошибок
Ваша функция paintNeeded отлично работает... чаще всего.
Но один из пользователей недавно случайно передал ей отрицательное число и получил отрицательный расход краски!
Пример:
func main() {
amount := paintNeeded(4.2, -3.0)
fmt.Printf("%0.2f liters neededn", amount)
}
func paintNeeded(width float64, height float64) float64 {
area := width * height
return area / 10.0
}
Похоже, функция paintNeeded и не подозревает, что переданный ей аргумент недействителен.
Она просто идет напролом, использует этот аргумент в своих вычислениях и возвращает недействительный результат.
Это создает проблемы — даже если вы знаете, где можно приобрести отрицательный объем краски, захочется ли вам использовать такую краску у себя дома?
Необходимо обнаруживать недопустимые значения аргументов и сообщать об ошибке.
Ранее были продемонстрированы функции, которые в дополнение к основному возвращаемому значению также возвращают второе значение — признак ошибки.
Например, функция strconv.Atoi пытается преобразовать строку в целое число.
Если преобразование прошло успешно, возвращается значение ошибки nil, означающее, что программа может продолжать работу.
Но если значение ошибки не равно nil, значит, строку невозможно преобразовать в число.
В таком случае мы решили вывести значение ошибки и прервать выполнение программы.
Пример:
guess, err := strconv.Atoi(input) //Входная строка преобразуется в целое число
if err != nil {
//Если обнаружена ошибка, вывести сообщение и прервать работу программы
log.Fatal(err)
}
Если мы хотим, чтобы при вызове функции paintNeeded происходило то же самое, необходимо реализовать две возможности:
- Создание значения, представляющего ошибку.
- Возвращение дополнительного значения из функции paintNeeded.
Нужно сначала разобраться с пакетом errors.
51. Ошибки и пакет erros
Значение ошибки представляет собой любое значение с методом Error, который возвращает строку.
Чтобы создать такое значение, проще всего передать строку функции New из пакета errors — функция создаст и вернет новое значение ошибки.
Если вызвать для полученного значения метод Error, вы получите строку, переданную errors.New
Пример:
package main
import (
"errors"
"fmt"
)
func main() {
err := errors.New("height can't be negative") //Создаем новое значение ошибки
fmt.Println(err.Error()) //Возвращает сообщение об ошибке
}
Но если значение ошибки передается функции из пакета fmt или log, скорее всего, вам не нужно будет вызвать его метод Error.
Функции пакетов fmt и log были написаны так, что они проверяют, содержит ли переданное им значение метод Error, и если содержит — выводят возвращаемое значение Error.
err := errors.New("height can't be negative")
fmt.Println(err) //Выводит сообщение об ошибке.
log.Fatal(err) //Тоже выводит сообщение об ошибке, после чего завершает программу.
Но если значение ошибки передается функции из пакета fmt или log, скорее всего, вам не нужно будет вызвать его метод Error.
Функции пакетов fmt и log были написаны так, что они проверяют, содержит ли переданное им значение метод Error,
и если содержит — выводят возвращаемое значение Error.
err := errors.New("height can't be negative")
fmt.Println(err) //Выводит сообщение об ошибке
log.Fatal(err) //Тоже выводит сообщение об ошибке, после чего завершает программу.
Если вам потребуется отформатировать числа или другие значения для использования в сообщениях об ошибках, воспользуйтесь функцией fmt.Errorf.
Функция вставляет значения в форматную строку так же, как это делает fmt.Printf или fmt.Sprintf,
но вместо вывода или возвращения строки она возвращает значение ошибки.
err := fmt.Errorf("a height of %0.2f is invalid", -2.33333)
fmt.Println(err.Error())
fmt.Println(err)
52. Объявление нескольких возвращаемых значений
Чтобы объявить функцию с несколькими возвращаемыми значениями,
заключите типы возвращаемых значений во второй набор круглых скобок в объявлении функции (после
круглых скобок с параметрами), разделяя их запятыми.
Круглые скобки вокруг возвращаемых значений можно опустить, если функция возвращает всего одно значение, но с несколькими возвращаемыми значениями они обязательны.
package main
import "fmt"
func manyReturns() (int, bool, string) {
return 1, true, "hello"
}
func main() {
myInt, myBool, myString := manyReturns()
fmt.Println(myInt, myBool, myString)
}
Вы также можете задать имя для каждого возвращаемого значения (по аналогии с именами параметров), если это поможет лучше понять их предназначение.
Именованные возвращаемые значения в основном служат документацией для программистов, читающих код
package main
import (
"fmt"
"math"
)
func floatParts(number float64) (integerPart int, fractionalPart float64) {
wholeNumber := math.Floor(number)
return int(wholeNumber), number - wholeNumber
}
func main() {
cans, remainder := floatParts(1.26)
fmt.Println(cans, remainder)
}
53. Использование множественных возвращаемых значений с функцией paintNeeded
Функция может возвращать несколько значений любых типов.
Впрочем, чаще всего эта возможность используется для возвращения основного значения,
за которым следует дополнительное значение, указывающее, обнаружила ли функция ошибку.
Дополнительному значению обычно присваивается nil, если выполнение прошло без проблем, или значение ошибки, если возникла ошибка.
Мы также будем следовать этим соглашениям в своей функции paintNeeded.
В объявлении функции будет указано, что она возвращает два значения, float64 и error. (Значения ошибок имеют тип error.)
В блоке функции мы прежде всего проверяем параметры.
Если хотя бы один из параметров width или height меньше 0, функция возвращает расход краски 0 (это значение бессмысленно, но что-то надо вернуть) и значение ошибки,
сгенерированное вызовом fmt.Errorf.
Проверка ошибок в начале функции позволяет легко пропустить остальной код функции вызовом return при возникновении проблем.
Если значения параметров допустимы, мы переходим к вычислению и возвращению расхода краски, как и прежде.
В коде функции встречается только одно отличие: наряду с расходом краски возвращается второе значение nil, указывающее на отсутствие ошибок.
package main
import "fmt"
func paintNeeded(width float64, height float64) (float64, error) {
if width < 0 {
return 0, fmt.Errorf("a width of %0.2f is invalid", width) //Если ширина имеет недопустимое значение, вернуть 0 и признак ошибки.
}
if height < 0 {
return 0, fmt.Errorf("a height of %0.2f is invalid", height) //Если высота имеет недопустимое значение, вернуть 0 и признак ошибки.
}
area := width * height
return area / 10.0, nil //Возвращает расход краски и значение «nil», которое указывает на отсутствие ошибок.
}
func main() {
amount, err := paintNeeded(4.2, -3.0)
fmt.Println(err) //Выводим значение ошибки (или «nil», если ошибки не было).
fmt.Printf("%0.2f liters neededn", amount)
}
54. Всегда обрабатывайте ошибки!
При передаче paintNeeded недопустимого аргумента вы получаете значение ошибки, которое выводится для просмотра пользователем.
Но при этом мы также получаем (недействительный) расход краски, который тоже выводится программой!
func main() {
amount, err := paintNeeded(4.2, -3.0) //err Этой переменной присваивается значение ошибки. // amount Присваивается 0 (бессмысленное значение).
fmt.Println(err) // Выводит ошибку
fmt.Printf("%0.2f liters neededn", amount) // Выводит бессмысленное значение!
}
Наряду со значением ошибки функция также обычно должна возвращать основное значение.
Но любые другие значения, возвращаемые вместе со значением ошибки, следует считать ненадежными и игнорировать.
Когда вы вызываете функцию, возвращающую значение ошибки, прежде всего необходимо убедиться в том, что это значение равно nil.
Если значение отлично от nil, значит, в программе возникла ошибка, которую необходимо обработать.
Как именно должна обрабатываться ошибка — зависит от ситуации.
Возможно, в случае с функцией paintNeeded лучше всего будет пропустить текущее вычисление и продолжить выполнение программы:
func main() {
amount, err := paintNeeded(4.2, -3.0)
if err != nil { //Если значение ошибки не равно nil, в программе возникли проблемы...
fmt.Println(err) //...поэтому выводим ошибку.
} else { // В противном случае значение ошибки будет равно nil...
fmt.Printf("%0.2f liters neededn", amount) //и можно спокойно вывести полученный расход краски.
}
// Дальнейшие вычисления...
}
Но в такой короткой программе вместо этого можно вызвать log.Fatal, чтобы вывести сообщение об ошибке и прервать выполнение.
func main() {
amount, err := paintNeeded(4.2, -3.0)
if err != nil { //Если значение ошибки не равно nil, в программе возникли проблем...
log.Fatal(err) //...выводим ошибку и прерываем выполнение программы.
}
fmt.Printf("%0.2f liters neededn", amount) .Этот код никогда не будет выполняться при возникновении ошибки.
}
Важно помнить, что возвращаемое значение всегда следует проверять, чтобы знать, произошла ли ошибка.
А что делать с ошибкой, зависит от вас!
55. Ломаем и изучаем
Пример кода:
package main
import (
"fmt"
"math"
)
func squareRoot(number float64) (float64, error) {
if number < 0 {
return 0, fmt.Errorf("can't get square root of negative number")
}
return math.Sqrt(number), nil
}
func main() {
root, err := squareRoot(-9.3)
if err != nil {
fmt.Println(err)
} else {
fmt.Printf("%0.3f", root)
}
}
0. Удалить один из аргументов return:
return math.Sqrt(number) // например nil
Ошибка:
# command-line-arguments
./03_prim.go:18:2: not enough arguments to return
have (float64)
want (float64, error)
Количество аргументов return всегда должно соответствовать количеству возвращаемых значений в объявлении функции.
1. Удалить одну из переменных, которым присваиваются возвращаемые значения:
root := squareRoot(-9.3) // удалили err
Ошибка:
# command-line-arguments
./03_prim.go:21:7: assignment mismatch: 1 variable but squareRoot returns 2 values
./03_prim.go:23:5: undefined: err
./03_prim.go:24:15: undefined: err
Если вы используете одно из возвращаемых значений функции, Go требует, чтобы вы использовали их все.
2. Удалить код, использующий одно из возвращаемых значений:
root, err := squareRoot(-9.3)
//if err != nil {
//fmt.Println(err)
//} else {
fmt.Printf("%0.3f", root)
//}
Ошибка:
# command-line-arguments
./05_dz.go:20:7: assignment mismatch: 1 variable but squareRoot returns 2 values
Go требует, чтобы каждая объявленная переменная использовалась в программе.
И эта особенность весьма полезна для работы с возвращаемыми значениями, потому что она предотвращает случайное игнорирование ошибок.
56. В параметрах функций хранятся копии аргументов
Как уже говорилось, при вызове функции с объявленными параметрами необходимо передать аргументы при вызове.
Значение каждого аргумента копируется в соответствующую переменную-параметр.
(Этот механизм в языках программирования иногда называют «передачей по значению».)
Во многих случаях этого достаточно.
Но если вы хотите передать значение переменной функции, чтобы функция каким-то образом изменила его, возникает проблема.
Функция может изменить только копию значения параметра, но не оригинал.
Таким образом, любые изменения, внесенные внутри функции, не будут видны за ее пределами!
Ниже приведена обновленная версия функции double, приведенной выше.
Она получает число, умножает его на 2 и выводит результат.
(Функция использует оператор *= , который работает аналогично += , но умножает значение из переменной вместо того, чтобы выполнять сложение.)
package main
import "fmt"
func main() {
amount := 6 //Аргумент передается функции
double(amount)
}
func double(number int) { //В параметрах сохраняется копия аргумента
number *= 2
fmt.Println(number) //Выводит удвоенное значение
}
Но предположим, вы хотите переместить команду вывода удвоенного значения из функции double в функцию, из которой она вызывается.
Такое решение работать не будет, потому что double изменяет только копию значения.
При попытке вывести значение в вызывающей функции будет выведено исходное значение, а не удвоенное!
package main
import "fmt"
func main() {
amount := 6
double(amount) //Функция передает аргумент
fmt.Println(amount) //Выводится исходное значение
}
func double(number int) { //Параметру присваивается копия аргумента
number *= 2 // Измен
}
Как же добиться того, чтобы функция изменяла исходное значение, хранящееся в переменной, вместо его копии?
Чтобы понять, как это делается, необходимо познакомиться с указателями.
57. Указатели
Оператор & (амперсанд) используется в Go для получения адреса переменной.
Например, следующий код инициализирует переменную, сначала выводит ее значение, а затем адрес переменной...
Пример кода:
package main
import "fmt"
func main() {
amount := 6
fmt.Println(amount) //Выводит значение переменной
fmt.Println(&amount) //Выводит адрес переменной
}
вывод кода:
6 //Значение переменной.
0x400011c010 //Адрес переменной.
Адрес можно получить для переменной любого типа.
Обратите внимание, все переменные имеют разные адреса.
Еще пример кода:
package main
import "fmt"
func main() {
var myInt int
fmt.Println(&myInt)
var myFloat float64
fmt.Println(&myFloat)
var myBool bool
fmt.Println(&myBool)
}
Вывод кода:
0x40000ba010
0x40000ba018
0x40000ba030
И что же собой представляют эти «адреса»?
Чтобы найти конкретный дом в плотно застроенном городе, вам нужно знать его адрес...
Память, выделяемая компьютером программе, так же переполнена, как и городские улицы.
Она забита значениями переменных: логическими значениями, целыми числами, строками и т. д.
Зная адрес переменной, вы сможете воспользоваться им для получения значения, хранящегося в переменной.
Адрес
|
0x1040a100 0x1040a108 0x1040a110 0x1040a118 0x1040a120 0x1040a128
true 6 ... ... ... 3.1415
|
значение, хранящееся по этому адресу!
!!! Значения, представляющие адреса переменных, называются указателями, потому что они указывают на область памяти, в которой хранится переменная.
58. Типы указателей
Тип указателя состоит из знака * и типа переменной, на которую ссылается указатель.
Например, тип указателя на переменную int записывается в виде *int (читается «указатель на int»).
С помощью функции reflect.TypeOf можно вывести типы указателей из приведенной ранее программы:
package main
import (
"fmt"
"reflect"
)
func main() {
var myInt int
fmt.Println(reflect.TypeOf(&myInt)) //Получает указатель на myInt и выводит тип указателя.
var myFloat float64
fmt.Println(reflect.TypeOf(&myFloat)) //Получает указатель на myFloat и выводит тип указателя.
var myBool bool
fmt.Println(reflect.TypeOf(&myBool)) //Получает указатель на myBool и выводит тип указателя.*
}
В программе можно объявлять переменные, содержащие указатели.
В таких переменных могут храниться только указатели на один конкретный тип переменной,
так что переменная может содержать только указатели *int, только указатели *float64 и т. д.
package main
import "fmt"
func main() {
myInt := 4 //Значение
myIntPointer := &myInt //Указатель
fmt.Println(myIntPointer) //Выводится сам указатель.
fmt.Println(*myIntPointer) //Выводится значение, на которое ссылается указатель.
myFloat := 98.6 //Значение
myFloatPointer := &myFloat //Указатель
fmt.Println(myFloatPointer) //Выводит сам указатель
fmt.Println(*myFloatPointer) //Выводится значение, на которое ссылается указатель.
myBool := true //Значение
myBoolPointer := &myBool ////Указатель
fmt.Println(myBoolPointer) //Выводит сам указатель
fmt.Println(*myBoolPointer) //Выводится значение, на которое ссылается указатель.
Как и с другими типами, при немедленном присваивании исходного значения переменной-указателю можно воспользоваться коротким объявлением переменной.
package main
import "fmt"
func main() {
var myBool bool
myBoolPointer := &myBool //Короткое объявление переменной-указателя.
fmt.Println(myBoolPointer)
}
59. Чтение или изменение значения по указателю
!!! Оператор * может использоваться для обновления значения по указателю.
package main
import "fmt"
func main() {
myInt := 4 //Значение
fmt.Println(myInt) //Вывести значение
myIntPointer := &myInt //Создаем указатель
*myIntPointer = 8 //Новое значение присваивается переменной, на которую ссылается указатель (myInt).
fmt.Println(*myIntPointer) //Выводится значение переменной, на которую ссылается указатель.
fmt.Println(myInt) //Значение переменной выводится напрямую.
}
/*
4 Исходное значение myInt.
8 Результат обновления *myIntPointer.
8 Обновление значения myInt (то же, что *myIntPointer).
*/
В приведенном коде команда *myIntPointer = 8 обращается к переменной,
на которую ссылается указатель myIntPointer (то есть переменной myInt) и присваивает ей новое значение.
Таким образом, обновляется не только значение *myIntPointer, но и myInt
60. Использование указателей с функциями
Указатели также можно возвращать из функций;
просто объявите возвращаемый тип функции как тип указателя.
Пример кода:
package main
import "fmt"
func createInt() *int {
var myInt = 100
return &myInt
}
func createPointer() *float64 {
var myFloat = 98.5
return &myFloat
}
func crS() *string {
var xX = "hello all"
return &xX
}
func main() {
var myFloatPointer *float64 = createPointer()
fmt.Println(*myFloatPointer)
var x *int = createInt()
fmt.Println(*x)
var x1 *string = crS()
fmt.Println(*x1)
}
Кстати говоря, в отличие от некоторых других языков, в Go можно вернуть указатель на переменную, локальную по отношению к функции.
И хотя эта переменная уже не находится в области видимости, пока у вас есть указатель, Go предоставит вам доступ к значению этой переменной.
package main
import "fmt"
func printPointer(myBoolPointer *bool) {
fmt.Println(*myBoolPointer)
}
func main() {
var myBool bool = true
printPointer(&myBool)
}
61. Проведем промежуточные итоги
Функции
Типы
Условные команды
Циклы
0. Объявление функций
Чтобы вызвать объявленную вами функцию в другой точке того же пакета,
введите имя функции и пару круглых скобок со списком аргументов (если он есть)
Функция может возвращать одно или несколько значений.
1. Указатели
Чтобы получить указатель на переменную, поставьте оператор & прямо перед именем переменной:
&myVaruable
Имена типов-указателей состоят из символа * и типа значения, на которое ссылается указатель
(*int, *bool и т.д.)
2. Функция fmt.Printf и fmt.Sprintf форматируют переданные им значения.
В первом аргументе передается форматная срока с глаголами (%d, %f, %s и т.д.),
на место которых подставляется отформатированные значения.
2.1 Глагол форматирования может содержать ширину:
минимальное количество символов, которые будет занимать отформатированное значение.
Например, глагол %12s определяет строку из 12 символов (дополненную пробелами),
%2d — целое число из двух цифр,
а %.3f — число с плавающей точкой, округленное до трех цифр в дробной части.
3. Если вы хотите, чтобы при вызовах вашей функции передавались аргументы,
необходимо объявить один или несколько параметров (с указанием типа каждого параметра) в объявлении функции.
Количество и тип аргументов всегда должны соответствовать количеству и типу параметров — в противном случае вы получите ошибку компиляции.
4. Если вы хотите, чтобы ваша функция возвращала одно или несколько значений,
объявите типы возвращаемых значений в объявлении функции.
5. К переменным, объявленным внутри функции, невозможно обратиться вне этой функции.
С другой стороны, внутри функции можно обращаться к переменным, объявленным за пределами функции (обычно на уровне пакета).
6. Если функция возвращает несколько значений, последнее значение обычно имеет тип error.
Значения ошибок содержат метод Error(), который возвращает строку с описанием ошибки.
7. По умолчанию функции возвращают значение ошибки nil, указывающее на отсутствие ошибок.
8. Чтобы обратиться к значению, на которое ссылается указатель, поставьте * перед именем:
*myPointer.
9. Если функция получает указатель в параметре и обновляет значение, на которое ссылается указатель, такое изменение будет видимо за пределами функции.
62. Пакеты Хранение кода пакетов
Пакеты нужны для хранения взаимосвязанного кода в одном месте.
Но пакеты нужны не только для организации кода.
Пакеты предоставляют простые средства для повторного использования кода в разных программах.
А еще это простой способ распространения кода среди разработчиков.
Инструменты Go ищут код пакетов в специальном каталоге (папке) на вашем компьютере, который называется рабочей областью.
По умолчанию рабочей областью является каталог с именем go в домашнем каталоге текущего пользователя.
Каталог рабочей области содержит три подкаталога:
- bin для хранения откомпилированных двоичных исполняемых программ.
- pkg для хранения откомпилированных двоичных файлов пакетов.
- src для хранения исходного кода Go.
В каталоге src код каждого пакета размещается в отдельном подкаталоге.
По соглашениям имя подкаталога должно совпадать с именем пакета (так что код пакета gizmo должен храниться в подкаталоге с именем gizmo).
Подкаталог каждого пакета должен содержать один или несколько файлов с исходным кодом.
Имена файлов могут быть любыми, но они должны иметь расширение .go.
домашний каталог пользователя
|
|_ go //каталог рабочей области.
|
|_ bin //Исполняемые программы
|
|_ pkg //Откомпилированный код пакетов
|
|_ src //Исходный код
|
|__ package1 //код пакета находится в отдельном каталоге.
|
|__ package2 //код пакета находится в отдельном каталоге.
|
|_ package2.go //каждый каталог пакета содержит один или несколько файлов с исходным кодом.
|_ plugin.go //каждый каталог пакета содержит один или несколько файлов с исходным кодом.
Вопрос:
Вы говорите, что в каталоге пакета могут находиться несколько файлов.
Что должен содержать каждый файл?
Ответ:
Все что угодно!
Весь код пакета можно хранить в одном файле, а можно разбить его на несколько файлов.
В любом случае они станут частью одного пакета.
63. Создание нового пакета
Попробуем создать пакет в рабочей области.
Это будет простой пакет с именем greeting, который выводит приветствия на разных языках.
При установке Go каталог рабочей области не создается по умолчанию, так что вам придется создать его самостоятельно.
Для начала перейдите в свой домашний каталог.
(Путь имеет вид C:Users<имя_пользователя> в большинстве систем Windows,
/Users/<имя_пользователя> на Mac и /home/<имя_пользователя> в большинстве систем Linux.)
Linux:
cd ~
mkdir -p go/src/greeting
vim go/src/greeting/greeting.go
-------------------------------
package greeting
import "fmt"
func Hello() {
fmt.Println("Hello!")
}
func Hi() {
fmt.Println("Hi!")
}
-------------------------------
Как и все файлы с исходным кодом, встречавшиеся вам до этого, файл начинается с директивы package.
Но в отличие от других файлов, этот код не является частью пакета main;
он принадлежит пакету с именем greeting.
64. Импорт пакета в программу
cd ~
mkdir go/src/hi
vim go/src/hi/main.go
-------------------
package main
import "greeting"
func main() {
greeting.Hello()
greeting.Hi()
}
----------------------
65. Файлы пакетов имеют одинаковую структуру
1. Директива package.
2. Директива import.
3. Собственно код программы
Пример в коде:
package main //Директива package.
import "fmt" //Директива import.
//Собственно код программы.
func main() {
fmt.Println("Hello, Go!")
}
0. Изменить имя каталога greeting на salutation
Ошибка:
main.go:3:8: cannot find package "greeting" in any of:
/usr/lib/go-1.15/src/greeting (from $GOROOT)
/home/pi/go/src/greeting (from $GOPATH)
Программа не будет работать, потому что:
Инструменты Go используют имя в пути импорта как имя каталога, из которого должен загружаться исходный код пакета.
Если имена не совпадают, то код не загрузится.
1. Изменить имя в строке package файла greeting на "package salutation"
Ошибка:
main.go:4:8: cannot find package "salutation" in any of:
/usr/lib/go-1.15/src/salutation (from $GOROOT)
/home/pi/go/src/salutation (from $GOPATH)
Программа не будет работать, потому что:
Содержимое каталога greeting загрузится как пакет с именем salutation.
Но поскольку в вызовах функций в main.go упоминается пакет greeting, вы получите сообщения об ошибке
2. Преобразовать имена функций в файлах greeting.go и main.go к нижнему регистру
func hello()
func hi()
greeting.hello()
greeting.hi()
Ошибка:
# command-line-arguments
./main.go:6:2: cannot refer to unexported name greeting.hello
./main.go:6:2: undefined: greeting.hello
./main.go:7:2: cannot refer to unexported name greeting.hi
./main.go:7:2: undefined: greeting.hi
Программа не будет работать, потому что:
Функции, имена которых начинаются с букв нижнего регистра, не экспортируются — это означает, что они могут использоваться только в своем пакете.
Чтобы в программе можно было использовать функцию из другого пакета, эта функция должна экспортироваться, а для этого ее имя должно начинаться с буквы верхнего регистра
66. Соглашения по выбору имен пакетов
Разработчикам, использующим пакет, придется вводить его имя каждый раз, когда они вызывают функцию из этого пакета.
(Вспомните fmt.Printf, fmt.Println, fmt.Print и т. д.)
Чтобы не возникало проблем, при выборе имен пакетов следует соблюдать несколько правил:
- Имя пакета должно быть записано только символами нижнего регистра.
- Имя следует сокращать, если его смысл очевиден (например, fmt).
- По возможности имя должно состоять из одного слова. Если необходимы два слова, они не должны разделяться символами подчеркивания,
а второе слово не должно начинаться с буквы верхнего регистра (пример — пакет strconv).
- Импортированные имена пакетов могут конфликтовать с именами локальных переменных, поэтому не используйте имя,
которое с большой вероятностью может быть выбрано пользователями пакета.
(Например, если бы пакет fmt назывался format, то импорт этого пакета создавал бы риск конфликта с локальной переменной format.)
Уточнение имен
При обращении к функции, переменной или чему-то еще, экспортируемому из другого пакета, необходимо уточнить имя функции или переменной,
поставив перед именем функции или переменной имя пакета.
Но при обращении к функции или переменной, определенной в текущем пакете, не следует уточнять имя пакета.
67. Константы
Многие пакеты экспортируют константы: именованные значения, которые не изменяются за время работы программы.
Объявление константы очень похоже на объявление переменной: в нем также указывается имя, необязательный тип и значение.
Тем не менее правила несколько отличаются:
- Вместо ключевого слова var используется ключевое слово const.
- Значение константы должно быть задано в момент ее объявления.
Вы не сможете присвоить его позднее, как с переменными.
- Для переменных доступен синтаксис короткого объявления :=, а у констант аналогичной конструкции не существует.
Имя константы Значение
| |
const TriangleSides int = 3
| |
| Тип
|
Ключевое слово «const»
Как и при объявлении переменных, тип можно опустить, он будет автоматически определен по присваиваемому значению:
const SquareSides = 4 //Присваивается целое число, поэтому для константы будет выбран тип «int»
Значение переменной может изменяться, но значение константы должно оставаться постоянным.
Попытка присвоить новое значение константе приведет к ошибке компиляции.
Эта особенность констант обеспечивает безопасность:
константы должны использоваться для значений, которые не должны изменяться.
Пример кода:
package main
import "fmt"
func main() {
const PentagonSides = 5
PentagonSides = 7
fmt.Println(PentagonSides)
}
Ошибка:
# command-line-arguments
./00_constanta.go:8:16: cannot assign to PentagonSides
Если ваша программа включает «фиксированные» значения литералов (особенно если эти значения используются в нескольких местах), подумайте о том, чтобы заменить их константами (даже если программа не разбита на пакеты).
Ниже приведен пакет с двумя функциями, в обеих функциях целочисленный литерал 7 представляет количество дней в неделе:
68. Вложенные каталоги и пути импорта пакетов
home
└── user
└── go
└── src
└── __a__
| │ └── a.go //Код пакета "a"
| |
| └────── b.go //Код пакета "b"
|
└─ main.go //Наша программа, использующая пакеты "a" и "b"
Пример кода b:
package deutsch
import "fmt"
func Hallo() {
fmt.Println("Hallo!")
}
func Hue() {
fmt.Println("Guten Tag!")
}
Пример код main:
package main
import (
"a"
"a/b"
)
func main() {
a.Hello()
a.Hi()
b.Hallo()
b.Hue()
}
69. Установка исполняемых файлов командой "go install"
При использовании команды "go run" программа должна быть сначала откомпилирована, как и все пакеты, от которых она зависит.
И весь откомпилированный код будет потерян после завершения программы.
Ранее была описана команда go build, которая компилирует и сохраняет исполняемый двоичный файл (файл, который может выполняться даже без установки Go).
Но если вы будете использовать ее слишком часто, ваша рабочая область будет забита исполняемыми файлами в случайных и неподходящих местах.
Команда go install также сохраняет откомпилированные бинарные версии исполняемых программ, но в четко определенном и легкодоступном месте:
в каталоге bin вашей рабочей области Go.
Просто передайте go install имя каталога из src, содержащего код исполняемой программы (то есть файлов .go, начинающихся с package main).
Программа будет откомпилирована, а исполняемый файл будет сохранен в стандартном каталоге.
!!! неважно, из какого каталога вы запустите "go install name_package" — компилятор будет искать каталог внутри каталога src
Когда компилятор Go видит, что файл в каталоге name_package содержит объявление "package main", он понимает, что это код исполняемой программы.
Он компилирует исполняемый файл и сохраняет результат в каталоге с именем bin в рабочей области Go.
Каталог bin будет создан автоматически, если он до этого не существовал.)
70. Переменная GOPATH и смена рабочих областей
На разных веб-сайтах можно увидеть, как разработчики говорят о "настройке GOPATH" при обсуждении рабочей области Go.
GOPATH — переменная среды, к которой инструменты Go обращаются за информацией о местонахождении рабочей области.
Большинство разработчиков хранит весь свой код Go в одной рабочей области и не меняет ее местонахождения по умолчанию.
Но при желании можно использовать GOPATH для перемещения рабочей области в другой каталог.
Переменная среды предназначена для хранения и чтения значений (как и переменные Go), но управляет ею операционная система, а не Go.
Некоторые программы настраиваются при помощи переменных среды; к их числу относится и компилятор Go.
Допустим, вместо домашнего каталога вы разместили свой пакет greeting в каталоге code в корневом каталоге своего жесткого диска.
И теперь вы хотите запустить файл main.go, который зависит от greeting.
Пример:
.
└── code
├── main.go
└── src
└── greeting
└── greeting.go
Код:
cat code/main.go
package main
import "greeting"
ifunc main() {
greeting.Hello()
greeting.Hi()
}
cat code/src/greeting/greeting.go
package greeting
import "fmt"
func Hello() {
fmt.Println("hrllo")
}
func Hi() {
fmt.Print("Hi")
}
Допустим, вместо домашнего каталога вы разместили свой пакет greeting в каталоге code в корневом каталоге своего жесткого диска.
И теперь вы хотите запустить файл main.go, который зависит от greeting.
Но вы получаете сообщение об ошибке.
В нем говорится, что пакет greeting не найден, так как компилятор продолжает искать пакет в подкаталоге go вашего домашнего каталога:
Ошибка:
main.go:2:8: cannot find package "greeting" in any of:
/usr/lib/go-1.15/src/greeting (from $GOROOT)
/home/pi/go/src/greeting (from $GOPATH)
71. Настройка GOPATH
Если ваш код хранится в другом каталоге (вместо каталога по умолчанию),
вы должны настроить компилятор Go и передать информацию о местонахождении кода.
Для этого можно воспользоваться переменной среды GOPATH, а конкретный способ зависит от операционной системы.
Системы Mac и Linux systems:
Для настройки переменной среды используется команда export.
В приглашении терминала введите команду:
export GOPATH="/code"
Для каталога с именем code в корневом каталоге жесткого диска используется путь "/code".
Если вы храните код в другом месте, укажите нужный путь.
Системы Windows:
Для настройки переменной среды используется команда set.
В приглашении командной строки введите команду:
set GOPATH="C:code"
Для каталога с именем code в корневом каталоге жесткого диска используется путь «C:code».
Если вы храните код в другом месте, укажите нужный путь.
Обратите внимание: описанные выше способы настраивают переменную среды GOPATH только для текущего окна терминала/командной строки.
Вам придется настраивать ее заново для каждого нового окна.
Впрочем, есть способы выполнить постоянную настройку переменной среды.
72. Публикация пакетов / конфликт подключения пакетов с одним именем
!!! В каталоге src рабочего пространства Go может быть только один каталог keyboard.
Похоже, может быть только один пакет с именем keyboard!
Пример:
home/user
└── go
└── src
├── keyboard
│ └── keyboard.go
├── script
│ └── main.go
└── git.net
└── keyboard
└── keyboard.go
Пример кода:
package main
import (
"fmt"
"git.net/keyboard" //Обновляем путь импорта.
"log"
)
func main() {
fmt.Print("Enter a grade: ")
grade, err := keyboard.GetFloat() //Здесь ничего не изменилось: имя пакета осталось прежним.
if err != nil {
og.Fatal(err)
}
//... еще какой то код
}
73. Загрузка и установка пакетов командой "go get"
У использования URL-адреса размещения пакета в качестве пути импорта есть еще одно преимущество.
У команды "go" существует еще одна субкоманда "go get", которая может автоматически загружать и устанавливать пакеты за вас.
Создадим репозиторий "Git" для описанного выше пакета "greeting" по следующему URL-адресу:
https://github.com/headfirstgo/greeting
Это означает, что на любом компьютере с установленным экземпляром Go необходимо ввести в терминале следующую команду:
go get github.com/headfirstgo/greeting
После команды "go get" следует URL-адрес репозитория с отсеченным сегментом «схемы» («https://»).
Команда подключается к "github.com", загружает репозиторий "Git" по пути "/headfirstgo/greeting" и сохраняет его в каталоге "src" вашей рабочей области "Go".
(Примечание:
если в вашей системе не установлена поддержка "Git", вам будет предложено установить ее при выполнении команды "go get".
Просто следуйте инструкциям на экране.
Команда "go get" также работает с репозиториями Subversion, Mercurial и Bazaar.)
Команда "go get" автоматически создает подкаталоги, необходимые для настройки подходящего пути импорта (каталог github.com, каталог headfirstgo и т. д.).
Пакеты, сохраненные в рабочей области Go, готовы к использованию в программах.
Например, если вы хотите использовать пакеты greeting, dansk и deutsch в программе, включите в нее директиву импорта, которая выглядит примерно так:
import (
"github.com/headfirstgo/greeting"
"github.com/headfirstgo/greeting/dansk"
"github.com/headfirstgo/greeting/deutsch"
)
Команда go get работает также и с другими пакетами.
0. Переходим нужный каталог:
cd /home/pi/githabmegafolder/c-test/02_lesson_golang/23_goget/go
1. Экспортируем GOPATH / каталог по умолчанию для go:
export GOPATH=$(pwd)
2. Проверить переменную GOPATH:
env | grep GOPATH
3. скачиваем пакеты:
go get github.com/headfirstgo/keyboard
go get github.com/headfirstgo/greeting
74. Чтение документации пакетов командой "go doc"
Введите команду "go doc", чтобы вывести документацию по любому пакету или функции.
Чтобы вывести документацию по пакету, передайте его путь импорта команде "go doc".
Например, информация о пакете "strconv" выводится командой "go doc strconv".
go doc -h
go doc -u http
go doc strconv
go doc strconv ParseFloat
go doc github.com/headfirstgo/keyboard
Команда go doc старается получить полезную информацию на основании анализа кода.
Имена пакетов и пути импорта включаются автоматически, как и имена функций, параметры и возвращаемые типы.
И все же команда go doc не умеет творить чудеса.
Если вы хотите, чтобы пользователи смогли узнать из документации о предназначении пакета или функции,
придется добавить эту информацию самостоятельно.
К счастью, это делается просто: нужно добавить в код документирующие комментарии.
Обычные комментарии Go, размещенные непосредственно перед директивой package или объявлением функции,
считаются документирующими комментариями и включаются в вывод go doc.
При добавлении документирующих комментариев следует соблюдать ряд правил:
- Комментарии должны состоять из полноценных предложений.
- Комментарии для пакетов должны начинаться со слова "Package", за которым следует имя пакета:
// Package mypackage enables widget management.
- Комментарии для функций должны начинаться с имени функции, которую они описывают:
// MyFunction converts widgets to gizmos.
- В комментарии также можно включать примеры кода, которые должны снабжаться отступами.
- Не включайте дополнительные символы для выразительности или форматирования (кроме отступов в примерах кода).
Документирующие комментарии будут выводиться в виде простого текста и должны форматироваться соответствующим образом.
75. go help
go help
go help gopath
go help list
76. Запуск сервера документации HTML командой "godoc"
WEB поиск:
https://pkg.go.dev/
https://pkg.go.dev/fmt
Программа, которая обслуживает раздел документации сайта golang.org, на самом деле доступна и на вашем компьютере.
Эта программа называется godoc (не путайте с командой go doc), и она автоматически устанавливается вместе с Go.
Программа godoc генерирует документацию HTML на основании кода основной установки Go и вашей рабочей области.
Она включает веб-сервер, который может передавать полученные веб-страницы браузеру.
(Не беспокойтесь, с настройками по умолчанию godoc не будет принимать подключения с других компьютеров, кроме вашего.)
Чтобы запустить godoc в режиме веб-сервера, введите в терминале команду godoc (еще раз: не перепутайте с go doc) со специальным параметром -http=:6060.
godoc -http=:6060
После того как сервер godoc будет запущен, введите URL-адрес
http://localhost:6060/pkg
Debian
apt-get install golang-golang-x-tools
Ubuntu
apt-get install golang-golang-x-tools
Arch Linux
pacman -S golang-godoc-1
pacman -S go-tools
Kali Linux
apt-get install golang-golang-x-tools
Fedora
dnf install golang-godoc-1
Raspbian
apt-get install golang-golang-x-tools
Display help for package "fmt":
godoc fmt
Display help for the function "Printf" of "fmt" package:
godoc fmt Printf
Serve documentation as a web server on port 6060:
godoc -http=:6060
Create an index file:
godoc -write_index -index_files=path/to/file
Use the given index file to search the docs:
godoc -http=:6060 -index -index_files=path/to/file
77. Проведем промежуточные итоги
Функции
Типы
Условные команды
Циклы
Объявления decloracion
Указатели
Пакеты
00. По умолчанию рабочей областью является каталог с именем go в домашнем каталоге пользователя.
01. Чтобы использовать в качестве рабочей области другой каталог, настройте переменную среды GOPATH.
02. Go использует три подкаталога в рабочей области:
в каталоге bin хранятся откомпилированные исполняемые программы, в каталоге pkg — откомпилированный код пакетов,
а в каталоге src — исходный код Go.
03. Имена подкаталогов каталога src формируют путь импорта пакета.
Имена вложенных каталогов разделяются символами / в пути импорта.
04. Имя пакета определяется директивами package в начале файла с исходным кодом в каталоге пакета.
За исключением пакета main, имя пакета должно совпадать с именем каталога, в котором он находится.
05. Имена пакетов должны записываться в нижнем регистре.
В идеале они состоят из одного слова.
06. Функции пакета могут вызываться за пределами пакета только в том случае, если они экспортированы.
Функция экспортируется, если ее имя начинается с буквы верхнего регистра.
07. Константой называется имя для обращения к значению, которое никогда не изменяется.
08. Команда "go install" компилирует код пакета и сохраняет его в каталоге pkg для пакетов общего назначения или в каталоге bin для исполняемых программ.
09. В качестве пути импорта пакета принято использовать URL-адрес размещения пакета.
В этом случае команда "go get" может находить, загружать и устанавливать пакеты, зная только их путь импорта.
10. Команда "go doc" выводит документацию пакетов.
В выходные данные "go doc" включаются документирующие комментарии в коде.
78. Массивы / arrays
Многие программы работают со списками.
Списки адресов.
Списки телефонных номеров.
Списки товаров.
Массив представляет собой набор значений, относящихся к одному типу.
Представьте себе таблетницу — вы можете класть и доставать таблетки в любое отделение,
но при этом ее удобно переносить как единое целое.
Значения, хранящиеся в массиве, называются элементами.
Вы можете создать массив строк, массив логических значений или массив любого другого типа Go (даже массив массивов).
Весь массив можно сохранить в одной переменной, а затем обратиться к любому нужному элементу.
В массивах хранятся наборы значений.
Массив содержит заранее заданное количество элементов, а его размер не может увеличиваться или уменьшаться.
Чтобы объявить переменную для хранения массива, следует указать количество хранящихся в нем элементов в квадратных скобках ([]),
а затем тип элементов в массиве.
Чтобы присвоить значения элементам массива или прочитать их позднее, необходимо каким-то образом указать, какой элемент вам нужен.
Элементы в массиве нумеруются, начиная с 0.
Номер массива называется его индексом.
Пример массив нот:
var notes [7]string
notes[0] = "do"
notes[1] = "re"
notes[2] = "mi"
fmt.Println(notes[0])
fmt.Println(notes[1])
Массив целых чисел:
var primes [5]int
primes[0] = 2
primes[1] = 3
fmt.Println(primes[0])
Массив значений time.Time:
var dates [3]time.Time
dates[0] = time.Unix(1257894000, 0)
dates[1] = time.Unix(1447920000, 0)
dates[2] = time.Unix(1508632200, 0)
fmt.Println(dates[1])
Нулевые значения в массивах
Как и в случае с переменными,
при создании массивов все содержащиеся в них значения инициализируются нулевым значением для типа,
содержащегося в массиве.
Так массив значений int по умолчанию заполняется нулями.
С другой стороны, нулевым значением для строк является пустая строка,
так что массив строковых значений по умолчанию заполняется пустыми строками.
Нулевые значения позволяют безопасно выполнять операции с элементами массивов, даже если им не были присвоены значения.
Например, в следующем массиве хранятся целочисленные счетчики.
Любой элемент можно увеличить на 1 даже без предварительного присваивания значения,
потому что мы знаем, что все значения счетчиков начинаются с 0.
var counters [3]int
counters[0]++ // Первый элемент увеличивается с 0 до 1.
counters[0]++ // Первый элемент увеличивается с 1 до 2.
counters[2]++ // Третий элемент увеличивается с 0 до 1.
fmt.Println(counters[0], counters[1], counters[2])
Вывод:
2 0 1
При создании массива все содержащиеся
в нем элементы инициализируются нулевым
значением для типа, хранящегося в массиве.
79. Литералы массивов
Если вам заранее известны значения, которые должны храниться в массиве,
вы можете инициализировать массив этими значениями в форме литерала массива.
Литерал массива начинается как тип массива — с количества элементов в квадратных скобках,
за которым следует тип элементов.
Далее в фигурных скобках идет список исходных значений элементов массива.
Значения элементов должны разделяться запятыми.
[3]int{9, 18, 27}
| | |
| | Список значений, разделенных запятыми.
| Тип элементов в массиве.
|
Количество элементов в массиве.
var notes [7]string = [7]string{"do", "re", "mi", "fa", "so", "la", "ti"}
fmt.Println(notes[3], notes[6], notes[0])
var primes [5]int = [5]int{2, 3, 5, 7, 11}
fmt.Println(primes[0], primes[2], primes[4])
Литералы массивов также позволяют использовать короткие объявления переменных с помощью :=.
Короткое объявление переменной.
notes := [7]string{"do", "re", "mi", "fa", "so", "la", "ti"}
primes := [5]int{2, 3, 5, 7, 11}
Литералы массивов могут распространяться на несколько строк, но перед каждым переносом строки в коде должна стоять запятая.
Запятая даже должна стоять после последнего элемента в литерале массива, если за ним следует перенос строки.
(На первый взгляд этот синтаксис выглядит неуклюже, но он упрощает последующее добавление новых элементов в коде.)
text := [3]string{ // Все это один массив.
"This is a series of long strings",
"which would be awkward to place",
"together on a single line", // Запятая в конце обязательна.
}
Когда вы занимаетесь отладкой кода, вам не нужно передавать элементы массивов Println
и другим функциям пакета fmt один за одним.
Просто передайте весь массив.
Пакет fmt содержит логику форматирования и вывода массивов.
(Пакет fmt также умеет работать с сегментами, картами и другими структурами данных, которые будут описаны позднее.)
var notes [3]string = [3]string{"do", "re", "mi"}
var primes [5]int = [5]int{2, 3, 5, 7, 11}
fmt.Println(notes)
fmt.Println(primes)
Возможно, вы также помните глагол "%#v", используемый функциями Printf и Sprintf, — он форматирует значения так, как они отображаются в коде Go.
При форматировании с "%#v" массивы отображаются в форме литералов массивов Go.
fmt.Printf("%#vn", notes)
fmt.Printf("%#vn", primes)
80. Обращение к элементам массива в цикле
Вы не обязаны явно записывать целочисленные индексы элементов массивов, к которым обращаетесь в своем коде.
В качестве индекса также можно использовать значение целочисленной переменной.
notes := [7]string{"do", "re", "mi", "fa", "so", "la", "ti"}
index := 1
fmt.Println(index, notes[index]) // Выводит элемент массива с индексом 1.
index = 3
fmt.Println(index, notes[index]) // Выводит элемент массива с индексом 3.
for i := 0; i <= 2; i++ {
fmt.Println(i, notes[i])
}
При обращении к элементам массивов через переменную необходимо действовать внимательно и следить за тем, какие значения индексов используются в программе.
Как упоминалось ранее, массивы содержат конкретное число элементов.
Попытка обратиться к индексу за пределами массива приводит к панике — ошибке, происходящей во время выполнения программы (а не на стадии компиляции).
81. Проверка длины массива функцией "len"
Написание циклов, которые ограничиваются только правильными индексами, сопряжено с определенным риском ошибок.
К счастью, есть пара приемов, которые упрощают этот процесс.
Во-первых, вы можете проверить фактическое количество элементов в массиве перед обращением к элементу.
Для этого можно воспользоваться встроенной функцией len, которая возвращает длину массива (количество содержащихся в нем элементов).
notes := [7]string{"do", "re", "mi", "fa", "so", "la", "ti"}
for i := 0; i < len(notes); i++ {
fmt.Println(i, notes[i])
}
Впрочем, и здесь существует некоторый риск ошибок.
Хотя len(notes) возвращает наибольший индекс, к которому вы можете обращаться,
равен 6 (потому что индексирование массивов начинается с 0, а не с 1).
При попытке обратиться по индексу 7 возникнет ситуация паники.
82. Безопасный перебор массивов в цикле "for...range".
В другом, еще более безопасном способе обработки всех элементов массива используется специальный цикл for...range.
В форме с range указывается переменная для хранения целочисленного индекса каждого элемента,
другая переменная для хранения значения самого элемента и перебираемый массив.
Цикл выполняется по одному разу для каждого элемента в массиве;
индекс элемента присваивается первой переменной, а значение элемента — второй переменной.
В блок цикла включается код для обработки этих значений.
for index, value := range myArray {
// Блок цикла.
}
Эта форма цикла for не содержит запутанных выражений инициализации, условия и завершения.
А поскольку значение элемента автоматически присваивается переменной, риск обращения к недействительному индексу массива исключен.
Форма цикла for с range читается безопаснее и проще, поэтому именно она чаще всего встречается при работе с массивами и другими коллекциями.
notes := [7]string{"do", "re", "mi", "fa", "so", "la", "ti"}
for index, note := range notes {
fmt.Println(index, note)
}
Цикл выполняется семь раз, по одному разу для каждого элемента в массиве notes.
Для каждого элемента переменной index присваивается индекс элемента,
а переменной note присваивается значение элемента. После этого мы выводим индекс и значение.
Помните, как при вызове функции с несколькими возвращаемыми значениями мы хотели проигнорировать одно из них?
Это значение присваивалось пустому идентификатору ( _ ),
чтобы компилятор Go просто отбросил это значение без выдачи сообщения об ошибке...
То же самое можно проделать со значениями из циклов "for...range".
Если вам не нужен индекс каждого элемента массива, присвойте его пустому идентификатору:
notes := [7]string{"do", "re", "mi", "fa", "so", "la", "ti"}
for index, note := range notes {
fmt.Println(index, note)
}
А если вам не нужна переменная для значения, замените ее пустым идентификатором:
83. Чтение текстового файла
Ранее мы использовали пакеты os и bufio стандартной библиотеки для чтения данных по строкам с клавиатуры.
Те же пакеты могут использоваться и для построчного чтения данных из текстовых файлов.
В своем любимом текстовом редакторе создайте новый файл с именем data.txt.
Запишите в файле три наших значения с плавающей точкой, по одному числу в строке.
cat > data.txt << "EOF"
71.8
56.2
89.5
EOF
Пример программы:
package main
import (
"bufio"
"fmt"
"log"
"os"
)
func main() {
file, err := os.Open("data.txt") //Файл данных открыва
if err != nil {
log.Fatal(err)
}
scanner := bufio.NewScanner(file)
//Цикл выполняется до того, как будет достигнут конец файла, а scanner.Scan вернет false
for scanner.Scan() { //Читает строку из файла
fmt.Println(scanner.Text()) //Выводит строку
}
// Если при закрытии файла произошла ошибка то сообщить о ней и завершить работу
err = file.Close() //Закрывает файл для освобождения ресурсов.
if err != nil {
log.Fatal(err)
}
if scanner.Err() != nil {
log.Fatal(scanner.Err())
}
}
Наша тестовая программа readfile.go успешно читает данные из файла data.txt и выводит их.
А теперь разберемся, как же она работает.
Сначала строка с именем открываемого файла передается функции os.Open.
Эта функция возвращает два значения: указатель os.File, представляющий открытый файл, и значение ошибки.
Как и в случае с другими функциями, если значение ошибки равно nil, это означает,
что файл был открыт успешно, но любое другое значение указывает на то,
что произошла ошибка (например, если файл отсутствует или не читается).
В таком случае программа выводит сообщение об ошибке и завершается.
84. Чтение текстового файла в массив
Пример кода:
// Пакет datafile предназначен для чтения данных из файлов.
//package datafile
package main
import (
"fmt"
"bufio"
"os"
"strconv"
)
// GetFloats читает значение float64 из каждой строки файла. ошибку.
func GetFloats(fileName string) ([3]float64, error) {
var numbers [3]float64 // Объявление возвращаемого массива.
file, err := os.Open(fileName) //Открывает файл с переданным именем.
if err != nil {
return numbers, err
}
i := 0 //Переменная для хранения индекса, по которому должно выполняться присваивание
scanner := bufio.NewScanner(file)
for scanner.Scan() {
numbers[i], err = strconv.ParseFloat(scanner.Text(), 64)
if err != nil {
return numbers, err
}
i++ //Переход к следующему индексу массива.
}
err = file.Close()
if err != nil {
return numbers, err
}
if scanner.Err() != nil {
return numbers, scanner.Err()
}
return numbers, nil //Если выполнение дошло до этой точки, значит, ошибок не было, поэтому программа возвращает массив чисел и значение ошибки «nil ».
}
func main() {
fileName := "data.txt"
fmt.Println("Hello readfile")
fmt.Println(GetFloats(fileName))
}
85. Чтение файла и выполнение программы average. Еще один пример:
//average вычисляет среднее значение
package main
import (
"bufio"
"fmt"
"os"
"strconv"
"log"
)
// GetFloats читает значение float64 из каждой строки файла. ошибку.
func GetFloats(fileName string) ([3]float64, error) {
var numbers [3]float64 // Объявление возвращаемого массива.
file, err := os.Open(fileName) //Открывает файл с переданным именем.
if err != nil {
return numbers, err
}
i := 0 //Переменная для хранения индекса, по которому должно выполняться присваивание
scanner := bufio.NewScanner(file)
for scanner.Scan() {
numbers[i], err = strconv.ParseFloat(scanner.Text(), 64)
if err != nil {
return numbers, err
}
i++ //Переход к следующему индексу массива.
}
err = file.Close()
if err != nil {
return numbers, err
}
if scanner.Err() != nil {
return numbers, scanner.Err()
}
return numbers, nil //Если выполнение дошло до этой точки, значит, ошибок не было, поэтому программа возвращает массив чисел и значение ошибки «nil».
}
func main() {
filename := "data.txt"
numbers, err := GetFloats(filename)
if err != nil {
log.Fatal(err)
}
var sum float64 = 0
for _, number := range numbers {
sum += number
}
sampleCount := float64(len(numbers))
fmt.Printf("Average: %0.2fn", sum/sampleCount)
}
Наша программа может обрабатывать только три значения!
cat > data1.txt << "EOF"
71.8
56.2
89.5
99.3
EOF
Пример ошибки:
panic: runtime error: index out of range [3] with length 3
goroutine 1 [running]:
main.GetFloats(0xd5676, 0x9, 0x0, 0x0, 0x0, 0x4d458, 0x162060)
/home/pi/githabmegafolder/c-test/02_lesson_golang/25_file/02_averange.go:25 +0x2e4
main.main()
/home/pi/githabmegafolder/c-test/02_lesson_golang/25_file/02_averange.go:46 +0x34
exit status 2
86. Промежуточные итоги:
Массивы:
Массив является списком значений определенного типа.
Каждое значение, хранимое в массиве, называется элементом массива.
Массив содержит фиксированное количество элементов.
Не существует возможности легко добавить новые элементы в массив.
Ключевые моменты:
- Чтобы объявить переменную-массив,
укажите длину массива в квадратных скобках и тип хранящихся в нем элементов:
var myArray [3]int
- Чтобы прочитать или присвоить значение элемента массива, укажите его индекс в квадратных скобках.
Индексы начинаются с 0, поэтому первый элемент myArray обозначается myArray[0].
- Как и переменные, по умолчанию все элементы массива инициализируются нулевым значением для типа элемента.
- Элементы массива можно инициализировать в момент создания;
для этого используется литерал массива:
[3]int{4, 9, 6}
- Если сохранить недопустимый индекс массива в переменной,
а потом попытаться обратиться к элементу с использованием этой переменной в
качестве индекса, возникнет ситуация паники — ошибка времени выполнения.
- Для получения количества элементов в массиве используется встроенная функция len.
Все элементы массива можно удобно обработать в специальном синтаксисе цикла "for... range".
Этот цикл перебирает все элементы и присваивает индекс и значение каждого элемента указанным вами переменным.
- При использовании цикла "for...range" можно игнорировать индекс или значение каждого элемента при помощи пустого идентификатора _.
- Функция os.Open открывает файл. Она возвращает указатель на значение os.File, представляющее открытый файл.
- При передаче значения os.File функции bufio.NewScanner возвращается значение bufio.Scanner.
Его методы Scan и Text используются для последовательного чтения файла по строкам.
87. Сегменты
Вы уже знаете, что в массив нельзя добавить новые элементы.
В нашей программе это создает настоящие проблемы, потому что количество значений данных в файле неизвестно заранее.
На помощь приходят сегменты Go.
Сегменты — разновидность коллекций, которые могут расширяться для хранения дополнительных элементов; а это как раз то, что нужно!
Оказывается, в Go существует структура данных, в которую можно добавлять новые значения, — она называется сегментом.
Как и массив, сегмент состоит из нескольких элементов, относящихся к одному типу.
В отличие от массивов, существуют функции, позволяющие добавлять новые элементы в конец сегмента.
Отличие сегмента от массива:
Фактически это уже знакомый синтаксис объявления массива, только без указания размера.
var myArray [5]int // Массив — обратите внимание на размер.
var mySlice []int // Сегмент — размер не задан
В отличие от переменных для массивов, объявление переменной для сегмента не приводит к автоматическому созданию сегмента.
Для этого следует вызвать встроенную функцию make.
Функции передается тип создаваемого сегмента (он должен соответствовать типу переменной, которой вы собираетесь присвоить сегмент)
и длина сегмента при создании.
Пример:
var notes []string
notes = make([]string, 7)
notes[0] = "do"
notes[1] = "re"
notes[2] = "mi"
fmt.Println(notes[2])
fmt.Println(notes[0])
Пример:
pr := make([]int, 5)
pr[0] = 99
pr[4] = 200
fmt.Println("pr[4] - pr[0] = ", pr[4]-pr[0])
Встроенная функция len для сегментов работает так же, как и для массивов.
Передайте len сегмент, и функция вернет его длину в виде целого числа.
Пример:
notes := make([]string, 7)
primers := make([]int, 5)
fmt.Println(len(notes))
fmt.Println(len(primers))
Циклы "for" и "for...range" работают с сегментами точно так же, как и с массивами:
Пример:
letters := []string{"a", "b", "c"}
for i := 0; i < len(letters); i++ {
fmt.Println(letters[i])
}
fmt.Println(" ")
for _, letter := range letters {
fmt.Println(letter)
}
88. Литералы сегментов
Как и с массивами, если вы заранее знаете, какими значениями должен быть заполнен сегмент в исходном
состоянии, то можете инициализировать сегмент этими значениями при помощи литерала сегмента.
Литерал сегмента очень похож на литерал массива, но если литерал массива содержит длину массива в квадратных скобках,
у литерала сегмента квадратные скобки пусты.
За пустыми скобками следует тип элементов, которые будут храниться в сегменте, и список исходных значений всех элементов, заключенный в фигурные скобки.
Вызывать функцию make необязательно, при использовании литерала сегмента ваш код создаст сегмент и заполнит его.
Сегмент:
[]int{9, 18, 27}
| | |
| | Список значений, разделенных запятыми.
| Тип элементов в сегменте
Пустая пара квадратных скобок
Пример:
notes := []string{"do", "re", "mi", "fa", "so", "la", "ti"} //Значения присваиваются с помощью литерала сегмента.
fmt.Println(notes[3], notes[6], notes[0])
primes := []int{ // Многострочный литерал сегмента.
2,
3,
5,
}
fmt.Println(primes[0], primes[1], primes[2])
Погодите!
Похоже, что сегменты могут делать все, что делают массивы, и в них можно добавлять элементы.
Тогда почему бы не ограничиться сегментами и не забыть про эту ерунду с массивами?
!!! Потому что сегменты построены на основе массивов.
!!! И вы не сможете понять, как работают сегменты, не понимая массивы.
Каждый массив существует на основе базового массива.
Данные сегмента на самом деле хранятся в базовом массиве, а сегмент всего лишь предоставляет «окно» для работы с некоторыми (или всеми) элементами массива.
Когда вы используете функцию make или литерал сегмента для создания сегмента,
базовый массив при этом создается автоматически (и вы не можете обратиться к нему иначе как через сегмент).
Но вы также можете создать массив самостоятельно, а затем создать сегмент на основе этого массива при помощи оператора сегмента.
Пример:
underlyingArray := [5]string{"a", "b", "c", "d", "e"}
slice1 := underlyingArray[0:3]
fmt.Println(slice1)
Пример:
underlyingArray := [5]string{"a", "b", "c", "d", "e"}
i, j := 1, 4
slice2 := underlyingArray[i:j]
fmt.Println(slice2)
У оператора сегмента предусмотрены значения по умолчанию как для начального, так и для конечного индексов.
Если начальный индекс не указан, будет использовано значение 0 позиции.
Пример:
underlyingArray := [5]string{"a", "b", "c", "d", "e"}
slice4 := underlyingArray[:3]
fmt.Println(slice4)
А если не указан конечный индекс, то в сегмент включаются элементы от начального индекса и до конца базового завершается.
Пример:
underlyingArray := [5]string{"a", "b", "c", "d", "e"}
slice5 := underlyingArray[1:]
fmt.Println(slice5)
89. Базовые массивы
Как упоминалось ранее, сам сегмент не содержит данных, это всего лишь «окно» для просмотра элементов базового массива.
Сегмент можно представить себе как микроскоп, направленный на определенную часть предметного стекла (базовый массив).
Когда вы берете сегмент базового массива, то «видите» только ту часть элементов массива, которая видна через этот сегмент.
Несколько сегментов могут существовать на основе одного базового массива.
В этом случае каждый сегмент становится «окном» для отдельного подмножества элементов массива. Сегменты даже могут перекрываться!
Присваивание нового значения элементу сегмента приводит к изменению соответствующего элемента в базовом массиве.
Если на один и тот же базовый массив указывают несколько сегментов, то и изменения элементов массива будут видны во всех сегментах.
Из-за этих потенциальных проблем обычно рекомендуется создавать сегменты с использованием make или литерала
сегмента (вместо того, чтобы создать массив и применять к нему оператор сегмента).
С make и литералами сегментов вам никогда не приходится иметь дела с базовым массивом.
90. Расширение сегментов функцией "append"
В Go существует встроенная функция append, которая получает сегмент и одно или несколько значений,
которые присоединяются в конец сегмента.
Функция возвращает но вый, расширенный сегмент со всеми элементами исходного сегмента и новыми элементами, добавленными в его конец.
Пример:
slice := []string{"a", "b"}
fmt.Println(slice, len(slice))
slice = append(slice, "c")
fmt.Println(slice, len(slice))
slice = append(slice, "d", "e")
fmt.Println(slice, len(slice))
Вам не нужно следить за тем, по какому индексу присваиваются новые значения, или за чем-нибудь еще!
Просто вызовите функцию append и передайте ей сегмент со значениями, которые добавляются в конец сегмента,
и вы получите новый расширенный сегмент.
Да, так просто!
Обратите внимание: возвращаемое значение append во всех случаях присваивается той же переменной сегмента,
которая передается append.
Таким образом предотвращается возможность непоследовательного поведения сегментов, возвращаемых append.
Базовый массив сегмента не может увеличиваться в размерах.
Если в массиве не остается места для добавления элементов, все элементы копируются в новый, больший массив, а сегмент обновляется,
чтобы он базировался на новом массиве.
Но поскольку все это происходит где-то за кулисами внутри функции append, невозможно простым способом определить,
имеет ли возвращенный сегмент тот же базовый массив, как и переданный сегмент, или другой.
Если в программе будут оставаться оба сегмента, это может привести к непредсказуемому поведению.
Пример:
s1 := []string{"s1", "s1"}
s2 := append(s1, "s2", "s2")
s3 := append(s2, "s3", "s3")
s4 := append(s3, "s4", "s4")
fmt.Println(s1, s2, s3, s4)
s4[0] = "XX"
fmt.Println(s1, s2, s3, s4)
По этой причине при вызове append возвращаемое значение обычно присваивается той же переменной сегмента, которая была передана append.
Если в программе хранится только один сегмент, то вам не придется беспокоиться о том, используют ли два сегмента один базовый массив!
Пример:
s1 := []string{"s1", "s1"}
s1 = append(s1, "s2", "s2")
s1 = append(s1, "s3", "s3")
s1 = append(s1, "s4", "s4")
fmt.Println(s1)
91. Сегменты и нулевые значения
Как и в случае с массивами, при обращении к элементу сегмента, которому не было присвоено значение, вы получите нулевое значение для этого типа.
Пример:
floatSlice := make([]float64, 10)
boolSlice := make([]bool, 10)
fmt.Println(floatSlice[9], boolSlice[5])
Пример:
var intSlice []int
var stringSlice []string
fmt.Printf("intSlice: %#v, stringSlice: %#vn", intSlice, stringSlice)
92. Аргументы командной строки
cd /home/user
| |
| аргумент
команда
cd -l /home/user
| | |
| | второй аргумент
| первый аргумент
команда
93. Получение аргументов командной строки из сегмента os.Args
Пример:
package main
import (
"fmt"
"os"
)
func main() {
fmt.Println(os.Args)
}
94. Использование аргументов командной строки в программе
// average2 вычисляет среднее значение.
// use: go run 01_average2.go 50 10 55 66 99 45 22 33 100
package main
import (
"fmt"
"log"
"os"
"strconv"
)
func main() {
arguments := os.Args[1:]
var sum float64 = 0
for _, argument := range arguments {
number, err := strconv.ParseFloat(argument, 64)
if err != nil {
log.Fatal(err)
}
sum += number //Число прибавляется к сумме
}
sampleCount := float64(len(arguments))
fmt.Printf("Average: %0.2fn", sum/sampleCount) //Вычисление среднего значения
}
95. Функции с переменным количеством аргументов
После знакомства с сегментами мы можем рассмотреть одну возможность Go, которая до сих пор явно не упоминалась.
Вы заметили, что при некоторых вызовах функций может передаваться разное количество аргументов?
Например, взгляните на функцию fmt.Println или append.
fmt.Println(1)
fmt.Println(1, 2, 3, 4, 5)
letters := []string{"a"}
letters = append(letters, "b")
letters = append(letters, "c", "d", "e", "f", "g")
fmt.Println(letters)
Как же это делают функции Println и append? Они объявляются как функции с переменным количеством параметров.
Таким функциям при вызове может передаваться разное количество аргументов.
Чтобы функция могла получать переменное количество аргументов, поставьте многоточие (...) перед типом
последнего (или единственного) параметра функции в ее объявлении.
Пример:
func myFunc(param1 int, param2 ...string) {
// код функции | |
} | тип
многоточие
Пример:
package main
import "fmt"
func severalInts(numbers ...int) {
fmt.Println(numbers)
}
func main() {
severalInts(1)
severalInts(1, 2, 3)
}
Функция также может получать один или несколько фиксированных аргументов.
Если при вызове переменную часть аргументов можно опускать (что приведет к созданию пустого сегмента),
фиксированные аргументы всегда обязательны, если опустить их, произойдет ошибка компиляции.
Переменным может быть только последний параметр в определении функции,
он не может предшествовать обязательным параметрам.
func mix(num int, flag bool, strings ...string) {
fmt.Println(num, flag, strings)
}
func main() {
mix(1, true, "a", "b")
mix(2, false, "a", "b", "c", "d")
}
96. Использование функций с переменным количеством аргументов (inRange, maximum)
Пример:
package main
import (
"fmt"
"math"
)
func maximum(numbers ...float64) float64 { //Получаем любое количесво аргументов float64
max := math.Inf(-1) //начинаем с очень низского значения
for _, number := range numbers {
if number > max {
max = number
}
}
return max
}
func main() {
fmt.Println(maximum(71.8, 56.2, 89.5))
fmt.Println(maximum(90.7, 89.8, 98.3, 99.2))
Пример:
package main
import "fmt"
func inRange(min float64, max float64, numbers ...float64) []float64 {
var result []float64
for _, number := range numbers {
if number >= min && number <= max {
result = append(result, number)
}
}
return result
}
func main() {
fmt.Println(inRange(1, 100, -12.5, 4.2, 0, 50, 100.3)) // Поиск аргументов от 1 до 100 (задают первые два числа
fmt.Println(inRange(-10, 10, 4.1, 12, -12, -5.2)) //Поиск аргументов от -10 до 10 (задают первые два числа)
97. Подведем итоги:
Массивы
Массив является списком значений определенного типа.
Каждое значение, хранимое в массиве называется элементом массива.
Массив содержит фиксированное количество элементов
Сегменты
Сегмент также представляет собой список элементов определенного типа,
но в отличии от массивов, у них предусмотрена возможность добавления и удаление элементов.
Сегмент не содержит данных сам по себе. Сегмент является всего лишь "окном" для работы
с элементами базового массива.
Ключевые моменты:
- Тип переменной-сегмента объявляется так же, как и тип переменной-массива, но без указания длины:
var mySlice []int
- В основном код работы с сегментами идентичен коду работы с массивами.
В частности, это относится к обращению к элементам, использованию нулевых значений,
передаче сегментов функции len и циклам "for...range".
- Литерал сегмента выглядит точно так же, как литерал массива, но без указания длины:
[]int{1, 7, 10}
- Для получения сегмента, содержащего элементы с i по j - 1 массива или сегмента,
можно воспользоваться оператором сегмента: s[i:j]
- Пакетная переменная os.Args содержит сегмент строк с аргументами командной строки,
с которыми была запущена текущая программа.
- Чтобы объявить функцию с переменным количеством аргументов, поставьте многоточие (...)
перед типом последнего параметра в объявлении функции.
Этому параметру будут присвоены все аргументы переменного набора в виде сегмента.
- При вызове функции с переменным количеством аргументов можно использовать
сегмент вместо переменного набора аргументов, для этого поставьте многоточие после сегмента:
inRange(1, 10, mySlice...)
98. Карты
Сваливать все в одну кучу удобно до тех пор, пока не потребуется что-нибудь найти.
Вы уже видели, как создавать списки значений в массивах и сегментах.
Вы знаете, как применить одну операцию к каждому значению в массиве или сегменте.
Но что, если требуется поработать с конкретным значением?
Чтобы найти его, придется начать с начала массива или сегмента и просмотреть.
Каждое. Существующее. Значение.
А если бы существовала разновидность коллекций, в которой каждое значение снабжается специальной меткой?
Тогда нужное значение можно было бы быстро найти по метке!
Для этого в go есть Карты!
Но хранение имен в сегментах создает одну проблему: для каждой строки файла необходимо просмотреть многие,
а то и все значения в сегменте names для сравнения.
Для небольших участков такое решение подойдет,
но на большом участке с множеством избирателей такое решение может оказаться слишком медленным!
Хранение данных в сегменте можно сравнить с большой стопкой документов,
вы сможете достать из стопки конкретный документ, но в худшем случае вам придется перебрать всю стопку до последнего документа.
В Go также существует другой способ хранения коллекций данных: карты.
Карта представляет собой коллекцию, в которой вы обращаетесь к значениям по ключу.
Ключи обеспечивают простой механизм извлечения данных из карты.
Такую коллекцию можно сравнить с архивом, в котором документы разложены по аккуратно подписанным папкам.
Если массивы и сегменты могут использовать в качестве индексов только числа,
то в карте ключом может быть любой тип (при условии, что значения этого типа можно сравнивать оператором ==).
К этой категории относятся числа, строки и т. д.
Все значения должны относиться к одному типу, и все ключи тоже должны иметь одинаковый тип, но типы ключей и значений вполне могут быть разными.
Чтобы объявить переменную для хранения карты,
введите ключевое слово map, за которым следуют квадратные скобки ([]) с типом ключа.
После квадратных скобок указывается тип значения.
Пример:
var myMap map[string]float64
MyMap - имя карты
map - ключевое слово
string - тип ключа
float64 - тип значения
Как и в случае с сегментами, объявление переменной-карты не приводит к автоматическому созданию карты,
для этого необходимо вызвать функцию make (ту же, которая используется для создания сегментов).
Вместо типа сегмента функции make можно передать тип создаваемой карты (он будет совпадать с типом переменной, которой карта будет присвоена).
var ranks map[string]int //Объявление переменной для карты
ranks = make(map[string]int) //Непосредственное создание карты
А может, вам будет проще воспользоваться коротким объявлением переменной:
ranks := make(map[string]int) //Создание карты и объявление переменной для ее хранения.
Синтаксис присваивания значений в карте и их последующей выборки имеет много общего с синтаксисом присваивания и чтения значений в массивах и сегментах.
Но если массивы и сегменты позволяют использовать в качестве индексов элементов только целые числа, то для ключей карт можно выбрать практически любой тип.
Примеры:
fmt.Println("nPrint map numbers:")
ranks := make(map[string]int)
ranks["gold"] = 1
ranks["silver"] = 2
ranks["bronze"] = 3
fmt.Println(ranks["bronze"])
fmt.Println(ranks["gold"])
fmt.Println("nPrint map letters:")
elements := make(map[string]string)
elements["H"] = "Hydrogen"
elements["Li"] = "Lithium"
fmt.Println(elements["Li"])
fmt.Println(elements["H"])
fmt.Println("nPrint map bool:")
isPrime := make(map[int]bool)
isPrime[4] = false
isPrime[7] = true
fmt.Println(isPrime[4])
fmt.Println(isPrime[7])
Литералы - это множественные значения
Литералы карт
Если набор ключей и значений, которыми должна инициализироваться карта, известен заранее,
то как и в случае с массивами и сегментами, вы можете воспользоваться литералом карты для ее создания.
Литерал карты начинается с типа карты (в форме map[ТипКлюча]ТипЗначения).
За ним следуют заключенные в фигурные скобки пары «ключ/значение», которыми должна инициализироваться карта.
Каждая пара «ключ/значение» состоит из ключа, двоеточия и значения.
Пары «ключ/значение» разделяются запятыми.
Ключ Ключ.
| |
myMap := map[string]float64{"a": 1.2, "b": 5.6}
| | |
Тип карты. Значение. Значение.
Пример:
ranks := map[string]int{"bronze": 3, "silver": 2, "gold": 1}
fmt.Println(ranks["gold"])
fmt.Println(ranks["bronze"])
elements := map[string]string{
"H": "Hydrogen",
"Li": "Lithium",
}
fmt.Println(elements["H"])
fmt.Println(elements["Li"])
Как и в случае с литералами сегментов, с пустыми фигурными скобками будет создана карта, пустая в исходном состоянии.
emptyMap := map[string]float64{}
99. Нулевые значения с картами
Как и в случае с массивами и сегментами, при обращении к ключу карты,
которому не было присвоено значение, вы получите нулевое значение.
numbers := make(map[string]int)
numbers["I've been assigned"] = 12
fmt.Printf("%#vn", numbers["I've been assigned"])
fmt.Printf("%#vn", numbers["I haven't been assigned"])
В зависимости от типа нулевое значение может быть отлично от 0.
Например, для карт со строковым типом значения нулевым значением будет пустая строка.
words := make(map[string]string)
words["I've been assigned"] = "hi"
fmt.Printf("%#vn", words["I've been assigned"])
fmt.Printf("%#vn", words["I haven't been assigned"])
Как и в случае с массивами и сегментами, нулевые значения упрощают работу со значениями в картах даже в том случае,
если им еще не было явно присвоено значение.
counters := make(map[string]int)
counters["a"]++
counters["a"]++
counters["c"]++
fmt.Println(counters["a"], counters["b"], counters["c"])
Нулевое значение для карты равно nil
Нулевым значением самой переменной, предназначенной для хранения карты, является nil.
Если объявить переменную для карты, но не присвоить ей значение, она будет содержать nil.
Это означает, что не существует карты, в которую можно было бы добавить новые ключи и значения.
Попытавшись выполнить такую операцию, вы получите ситуацию паники.
Ошибка:
map[int]string(nil)
panic: assignment to entry in nil map
goroutine 1 [running]:
main.main()
/home/pi/githabmegafolder/c-test/02_lesson_golang/29_maps/07_maps_err_nil.go:8 +0x94
exit status 2
Прежде чем пытаться добавлять ключи и значения, создайте карту функцией make или с помощью литерала карты и присвойте ее переменной.
var myMap map[int]string = make(map[int]string)
myMap[3] = "three"
fmt.Printf("%#vn", myMap)
100. Как отличить нулевые значения от присвоенных
Нулевые значения удобны, но иногда из-за них бывает трудно определить, было ли присвоено нулевое значение для заданного ключа.
Пример:
package main
import "fmt"
func status(name string) {
grades := map[string]float64{"Alma": 0, "Rohit": 86.5}
grade := grades[name]
if grade < 60 {
fmt.Printf("%s is failing!n", name)
}
if grade > 60 {
fmt.Printf("%s grade > 60n", name)
}
}
func main() {
status("Alma") //Ключ которому присвоено 0
status("Carl") //Не создавали ключ с таким именем
status("Rohit")
}
Для подобных ситуаций обращение к ключу карты может возвращать второе (логическое) значение.
Это значение равно true, если возвращаемое значение было реально присвоено в карте, или false, если возвращаемое значение просто представляет нулевое значение по умолчанию.
Большинство разработчиков Go присваивает это логическое значение переменной с именем ok (потому что это удобное и короткое имя).
Пример:
counters := map[string]int{"a": 3, "b": 0}
var value int
var ok bool
value, ok = counters["a"]
fmt.Println(value, ok)
value, ok = counters["b"]
fmt.Println(value, ok)
value, ok = counters["c"]
fmt.Println(value, ok)
Если вы хотите просто проверить, присутствует значение в карте или нет, то вы можете проигнорировать само значение, присвоив его пустому идентификатору _.
Пример:
counters := map[string]int{"a": 3, "b": 0}
var ok bool
_, ok = counters["b"]
fmt.Println(ok)
_, ok = counters["c"]
fmt.Println(ok)
По второму возвращаемому значению можно решить, следует ли интерпретировать значение, полученное из карты, как присвоенное значение,
которое просто случайно совпало с нулевым значением этого типа, или же это значение не присваивалось.
Ниже приведена обновленная версия кода, которая перед выводом сообщения о провале проверяет, было ли присвоено значение по заданному ключу:
Пример:
package main
import "fmt"
func status(name string) {
grades := map[string]float64{"Alma": 0, "Rohit": 86.5}
grade, ok := grades[name]
if !ok {
fmt.Printf("No grade recorded for %s.n", name)
} else if grade < 60 {
fmt.Printf("%s is failing!n", name)
}
}
func main() {
status("Alma")
status("Carl")
}
101. Удаление пар "ключ/значение" функцией "delete"
Возможно, после присваивания значения для ключа в какой-то момент вы захотите удалить его из карты.
Go предоставляет для этой цели встроенную функцию delete.
Передайте функции delete два аргумента:
карту, из которой удаляется ключ, и удаляемый ключ.
Ключ вместе с соответствующим значением удаляется из карты.
В следующем коде мы присваиваем значения для ключей в двух разных картах, а затем снова удаляем их.
После этого при попытке обращения по этим ключам будет получено нулевое значение (0 для карты ranks, false для карты isPrime).
Вторичное логическое значение равно false в обоих случаях, что указывает на отсутствие ключа.
Пример:
var ok bool
ranks := make(map[string]int)
var rank int
ranks["bronze"] = 3
rank, ok = ranks["bronze"]
fmt.Printf("rank: %d, ok: %vn", rank, ok)
delete(ranks, "bronze")
rank, ok = ranks["bronze"]
fmt.Printf("rank: %d, ok: %vn", rank, ok)
isPrime := make(map[int]bool)
var prime bool
isPrime[5] = true
prime, ok = isPrime[5]
fmt.Printf("prime: %v, ok: %vn", prime, ok)
delete(isPrime, 5)
prime, ok = isPrime[5]
fmt.Printf("prime: %v, ok: %vn", prime, ok)
102. Циклы "for...range" с картами
for key, value := range myMap {
// Блок цикла.
}
Цикл for...range предоставляет простой способ перебора ключей и значений карты.
Предоставьте переменную для хранения каждого ключа, другую переменную для хранения соответствующего значения — и цикл автоматически переберет все элементы карты.
Пример:
package main
import "fmt"
func main() {
grades := map[string]float64{"Alma": 74.2, "Rohit": 86.5, "Carl": 59.7}
for name, grade := range grades {
fmt.Printf("%s has a grade of %0.1f%%n", name, grade)
}
}
Если вы хотите перебрать только ключи, опустите переменную для хранения значений:
Пример:
package main
import "fmt"
func main() {
grades := map[string]float64{"Alma": 74.2, "Rohit": 86.5, "Carl": 59.7}
for name := range grades {
fmt.Println(name)
}
}
А если нужны только значения, укажите для ключей пустой идентификатор _:
Пример:
package main
import "fmt"
func main() {
grades := map[string]float64{"Alma": 74.2, "Rohit": 86.5, "Carl": 59.7}
for _, grade := range grades {
fmt.Println(grade)
}
}
103. Цикл "for...range" обрабатывает карты в случайном порядке!
Пример:
package main
import "fmt"
func main() {
box := map[int]string{1: "a", 2: "b", 3: "c"}
for k, x := range box {
fmt.Println(k, "==", x)
}
}
С этим примером связана одна потенциальная проблема.
Если сохранить приведенный пример в файле и запустить его командой "go run", выясняется, что ключи и значения
карты выводятся в случайном порядке.
При многократном запуске программы вы будете каждый раз получать новый порядок.
Цикл "for...range" обрабатывает ключи и значения карты в случайном порядке, так как карта является неупорядоченной коллекцией ключей и значений.
Используя цикл "for...range" с картой, вы никогда не знаете, в каком порядке получите доступ к ее содержимому!
Иногда это нормально, но если вам требуется более последовательное упорядочение,
соответствующий код придется написать самостоятельно.
Для этого она использует два разных цикла for.
Первый цикл перебирает все ключи в карте, игнорируя значения, и добавляет их в сегмент строк.
Затем сегмент передается функции Strings пакета sort, которая сортирует их на месте в алфавитном порядке.
Пример:
package main
import (
"fmt"
"sort"
)
func main() {
grades := map[string]float64{"Alma": 74.2, "Rohit": 86.5, "Carl": 59.7}
var names []string
for name := range grades {
names = append(names, name)
}
sort.Strings(names)
for _, name := range names {
fmt.Printf("%s has a grade of %0.1f%%n", name, grades[name])
}
}
104. Подведем итоги.
Карты
Карты представляет собой коллекцию, в которой каждое значение хранится с соответствующим ключом.
Если массивы и сегменты могут использовать в качестве индексов только целые числа, для ключей карты может использовать(почти) любой тип.
Все ключи карты должны относится к одному типу и все значения тоже должны относится к одному типу, но тип ключей не обязан совпадать с типом значений.
Ключевые моменты:
- При объявлении переменной для карты необходимо указать типы ключей и значений:
var myMap map[string]int
- Чтобы создать новую карту, вызовите функцию make с типом карты:
myMap = make(map[string]int)
- Чтобы присвоить значение в карте, укажите ключ, по которому присваивается значение, в квадратных скобках:
myMap["my key"] = 12
- Чтобы прочитать значение из карты, также следует указать ключ:
fmt.Println(myMap["my key"])
- Инициализацию карты можно совместить с ее созданием при помощи литерала карты:
map[string]int{"a": 2, "b": 3}
- Как и в случае с массивами и сегментами, при обращении к ключу карты, для которого не было присвоено
значение, вы получите нулевое значение.
- При получении значения от карты может возвращаться второе необязательное логическое значение, которое
указывает, было ли это значение присвоено или же представляет нулевое значение по умолчанию:
value, ok := myMap["c"]
- Если вы хотите только проверить, связано ли с ключом значение, проигнорируйте значение с использованием пустого идентификатора _:
_, ok := myMap["c"]
- Чтобы удалить ключи и соответствующие значения из карты, используйте встроенную функцию delete:
delete(myMap, "b")
- Циклы "for...range" могут использоваться с картами по аналогии с тем, как они используются с массивами или сегментами.
Вы предоставляете только одну переменную, которой будет последовательно присваиваться каждый ключ, и вторую переменную,
которой будет последовательно присваиваться каждое значение.
for key, value := range myMap {
fmt.Println(key, value)
}
105. Структуры
Если вам нужно хранить смешанные значения разных типов, то массивы, сегменты и карты не подойдут.
Их можно настроить только для хранения значений одного типа.
Однако в Go существует способ решения этой проблемы...
Иногда требуется хранить вместе несколько типов данных.
Сначала вы познакомились с сегментами, предназначенными для хранения списков.
Затем были рассмотрены карты, связывающие список ключей со списком значений.
Но обе структуры данных позволяют хранить значения только одного типа, а в некоторых ситуациях требуется сгруппировать значения нескольких типов.
Например, в почтовых адресах названия улиц (строки) группируются с почтовыми индексами (целые числа).
Или в информации о студентах имена (строки) объединяются со средними оценками (вещественные числа).
Сегменты и карты не позволяют смешивать разные типы. Тем не менее это возможно при использовании другого типа данных, называемого структурой.
И тогда мы решили просто соединить типы string, int и bool!
И это отлично сработало!
Передавать все эти значения гораздо удобнее, когда они являются частью одной структуры!
106. Структуры формируются из значений МНОГИХ типов
Структура представляет собой значение, которое строится из других значений разных типов.
Если в сегменте могут храниться только строковые значения, а в карте — только целочисленные значения,
вы можете создать структуру для хранения строковых значений, значений int, float64, bool и т. д. — и все это в одной удобной группе.
Тип структуры объявляется ключевым словом struct, за которым следуют фигурные скобки.
В фигурных скобках определяются одно или несколько полей: значений, группируемых в структуре.
Определение каждого поля размещается в отдельной строке и состоит из имени поля,
за ним следует тип значения, которое будет храниться в этом поле.
struct {
field1 string
field2 int
}
Тип структуры может использоваться в качестве типа объявляемой переменной.
В этом коде объявляется переменная с именем myStruct для хранения структуры с полем number типа
float64, полем word типа string и полем toggle типа bool:
Пример:
package main
import "fmt"
func main() {
var myStruct struct { // Объявление переменной с именем "myStruct".
//Переменная «myStruct» может хранить структуры, состоящие из поля float64 с именем «number», поля string с именем «word» и поля bool с именем «toggle».
number float64
world string
toggle bool
}
fmt.Printf("%#vn", myStruct)
}
!!! Не беспокойтесь о количестве пробелов между именами и типами полей структур.
Когда вы записываете поля структуры, поставьте один пробел между именем поля и его типом.
Когда вы выполните команду "go fmt" для своего файла (а это следует делать всегда),
команда вставит дополнительные пробелы, чтобы все типы были выровнены по вертикали.
Выравнивание всего лишь упрощает чтение кода:
его смысл при этом совершенно не изменяется!
Пример:
var aStruct struct {
shortName int
longerName gloat64
longestName string
}
107. Обращения к полям структуры
Теперь вы знаете, как определяются структуры.
Но чтобы использовать структуру в программе, необходимо каким-то образом сохранять новые значения в полях структуры и после этого читать их.
До настоящего момента мы использовали оператор "точка" для обозначения функций, принадлежащих другому пакету, или методов,
принадлежащих некоторому значению:
fmt.Println("hi")
|
точка //Вызов функции, принадлежащей пакету "fmt"
var myTime time.Time
myTime.Year()
|
точка // Вызов метода, принадлежащего значению "Time"
Аналогичным образом оператор "точка" может использоваться для обозначения полей, принадлежащих структуре.
Этот синтаксис подходит как для присваивания значений, так и для их чтения.
Значение-структура.
| Имя поля
| |
myScruct.number = 3.14
fmt.Println(myStruct.number)
| |
| Имя поля
Значение-структура
Теперь мы можем воспользоваться оператором «точка» для присваивания значений всем полям myStruct и их последующего вывода:
package main
import "fmt"
func main() {
var myStruct struct {
number float64
word string
toggle bool
}
myStruct.number = 3.14
myStruct.word = "pie"
myStruct.toggle = true
fmt.Println(myStruct.number)
fmt.Println(myStruct.word)
fmt.Println(myStruct.toggle)
}
Хранение данных подписчиков в структуре
Итак, вы знаете, как объявить переменную для хранения структуры и как присваивать значения ее полям.
Теперь мы можем создать структуру для хранения данных подписчиков журнала.
Начнем с определения переменной с именем subscriber.
Эта переменная будет иметь структурный тип с полями name (string), rate (float64) и active (bool).
После объявления переменной и ее типа к полям структуры можно обращаться при помощи оператора «точка».
Каждому полю присваивается значение соответствующего типа, после чего программа выводит значения.
var subscriber struct {
name string
rate float64
active bool
}
subscriber.name = "Aman Singh"
subscriber.rate = 4.99
subscriber.active = true
fmt.Println("Name:", subscriber.name)
fmt.Println("Monthly rate:", subscriber.rate)
fmt.Println("Active?", subscriber.active)
Хотя данные подписчиков состоят из значений нескольких типов, структуры позволяют объединить их в одном удобном пакете!
108. Определения типов и структуры
Определения типов позволяют создавать собственные типы.
Они создают новый определяемый тип на основе базового типа.
И хотя в качестве базового может использоваться любой тип (например, float64, string или даже сегменты или карты), в этой главе мы сосредоточимся на использовании структурных типов как базовых.
Другие базовые типы будут использоваться после того, как мы поближе познакомимся с определениями типов в следующей главе.
Ключевое слово «type».
| Имя определяемого типа.
| |
type myType struct {
// поля |
} |
Базовый тип.
Чтобы написать определение типа, используйте ключевое слово type, за которым следует имя нового определяемого типа и имя базового типа, на основе которого он должен создаваться.
Если в качестве базового используется тип структуры, укажите ключевое слово struct со списком определений полей,
заключенным в фигурные скобки — по аналогии с тем, как это делалось при объявлении переменных для структур.
Определения типов, как и переменные, могут записываться внутри функций.
Но в этом случае область видимости определения ограничивается блоком этой функции,
что означает, что его нельзя будет использовать за пределами функции.
По этой причине типы обычно определяются вне любых функций, на уровне пакета.
Простой пример: в приведенном ниже коде определяются два типа — part и car.
Каждый определяемый тип использует структуру в качестве базового типа.
Затем в функции main объявляется переменная porsche типа car и переменная bolts типа part.
Переписывать длинные определения структур при объявлении переменных не нужно;
мы просто используем имена определяемых типов.
package main
import "fmt"
type part struct {
description string
count int
}
type car struct {
name string
topSpeed float64
}
func main() {
var porsche car
porsche.name = "Porsche 911 R"
porsche.topSpeed = 323
fmt.Println("Name:", porsche.name)
fmt.Println("Top speed:", porsche.topSpeed)
var bolts part
bolts.description = "Hex bolts"
bolts.count = 24
fmt.Println("Description:", bolts.description)
fmt.Println("Count:", bolts.count)
}
После того как переменные будут объявлены, мы можем присваивать значения полям их структур и читать их, как это делалось в предыдущих программах.
Ранее для того, чтобы создать несколько переменных для хранения данных подписчиков в структурах,
нам приходилось полностью записывать тип структуры (включая все ее поля) для каждой переменной.
var subscriber1 struct { //Определение типа структуры.
name string
rate float64
active bool
}
// ...
var subscriber2 struct { //Определение идентичного типа.
name string
rate float64
active bool
}
// ...
Но теперь мы можем определить тип subscriber на уровне пакета.
Тип структуры записывается только один раз, как базовый тип для определяемого типа.
Когда дойдет до объявления переменных, тип структуры не нужно будет записывать снова, достаточно указать subscriber в качестве типа.
Повторять все определение структуры уже не нужно!
package main
import "fmt"
type subscriber struct { //Определение типа с именем "subscriber".
//Тип структуры используется для переменных как базовый для определения типа.
name string
rate float64
active bool
}
func main() { //Объявление переменной типа "subscriber".
var subscriber1 subscriber
subscriber1.name = "Aman Singh"
fmt.Println("Name:", subscriber1.name)
var subscriber2 subscriber //Тип "subscriber" также использу-ется для второй переменной.
subscriber2.name = "Beth Ryan"
fmt.Println("Name:", subscriber2.name)
}
Возможности определяемых типов не ограничиваются типами переменных.
Определяемые типы также могут использоваться для параметров функций и возвращаемых значений.
Ниже снова приведен тип part с функцией showInfo, которая выводит поля part.
Функция получает один параметр с типом part.
Внутри showInfo мы обращаемся к полям переменной-параметра точно так же, как к полям любой другой структурной переменной.
package main
import "fmt"
type part struct {
description string
count int
}
func showInfo(p part) { //Объявление одного параметра с типом «part».
fmt.Println("Description:", p.description)
fmt.Println("Count:", p.count)
}
func main() {
var bolts part //Создается значение «part».
bolts.description = "Hex bolts"
bolts.count = 24
showInfo(bolts) //Тип «part» пере-дается функции
}
А здесь функция minimumOrder создает значение part с заданным описанием description и заранее определенным значением поля count.
Тип part также объявляется возвращаемым типом minimumOrder, чтобы функция могла вернуть созданную структуру.
package main
import "fmt"
// Директивы package и imports, определения типов пропущены
type part struct {
description string
count int
}
func minimumOrder(description string) part { //Объявляется одно возвращаемое значение типа «part».
var p part //Создание нового значения «part».
p.description = description
p.count = 100
return p //Функция возвращает тип «part».
}
func main() {
p := minimumOrder("Hex bolts") //Вызывает minimumOrder. Для сохранения возвращаемого значения «part» использу-ется короткое определение переменной.
fmt.Println(p.description, p.count)
}
Рассмотрим пару функций, которые работают с типом subscriber.
Функция printInfo получает значение subscriber в параметре и выводит значения полей структуры.
Также имеется функция defaultSubscriber, которая создает новую структуру subscriber и заполняет ее значениями по умолчанию.
Функция получает строковый параметр с именем name и использует его для инициализации поля name нового значения subscriber.
Затем она заполняет поля rate и active значениями по умолчанию.
Наконец, функция возвращает заполненную структуру subscriber на сторону вызова.
package main
import "fmt"
type subscriber struct {
name string
rate float64
active bool
}
//Объявляется один параметр
//с типом «subscriber».
func printInfo(s subscriber) {
fmt.Println("Name:", s.name)
fmt.Println("Monthly rate:", s.rate)
fmt.Println("Active?", s.active)
}
func defaultSubscriber(name string) subscriber { //Возвращает значение «subscriber».
var s subscriber //Создается новое значение «subscriber».
s.name = name
s.rate = 5.99
s.active = true
return s //Возвращает «subscriber».
}
func main() {
subscriber1 := defaultSubscriber("Aman Singh") //Создает subscriber с задан-ным значением name.
subscriber1.rate = 4.99 //Использует заданное значение rate.
printInfo(subscriber1) //Вывод значений полей
subscriber2 := defaultSubscriber("Beth Ryan") //Создает subscriber с задан-ным значением name.
printInfo(subscriber2) //Вывод значений полей.
}
В функции main имя подписчика передается defaultSubscriber для получения новой структуры subscriber.
Один подписчик пользуется льготной ставкой оплаты, поэтому это поле структуры заполняется напрямую.
Заполненные структуры subscriber передаются printInfo для вывода их содержимого.
109. Изменение структуры в функции
Наши друзья в Gopher Fancy попробовали написать функцию, которая получает структуру в параметре и обновляет одно из полей этой структуры.
package main
import "fmt"
type subscriber struct {
name string
rate float64
active bool
}
func applyDiscount(s subscriber) {
s.rate = 4.99 //Получает параметр «subscriber».
}
func main() {
var s subscriber
applyDiscount(s) //Пытается присвоить полю «rate» структуры «subscriber» значение 4.99
fmt.Println(s.rate) //Поле остается равным 0!
}
Помните, как мы пытались написать функцию double, которая получает число и удваивает его?
После возвращения из функции число снова возвращалось к исходному значению!
Тогда мы упомянули о том, что в Go используется «передача по значению»
это означает, что параметры функций получают копию аргументов, с которыми вызывалась функция.
Если функция изменяет значение параметра, то изменится копия, а не оригинал.
110. Использование указателей в структуре:
Используя указатели, вы также можете добиться того, чтобы функция обновляла передаваемую структуру.
Пример функции:
package main
import "fmt"
type subscriber struct {
name string
rate float64
active bool
}
func applyDiscount(s *subscriber) { // Получает указатель на структуру, а не саму структуру.
s.rate = 4.99 //Обновляет поле структуры.
}
func main() {
var s subscriber
applyDiscount(&s) //Передается указатель, а не структура.
fmt.Println(s.rate)
}
Ниже приведена обновленная версия функции applyDiscount, которая должна работать правильно.
Мы обновляем параметр s, чтобы он содержал указатель на структуру subscriber вместо самой структуры.
После этого обновляется значение в поле rate структуры.
В main функция applyDiscount вызывается с передачей указателя на структуру subscriber.
А при выводе значения в поле rate структуры становится видно, что оно было успешно обновлено!
111. Обращение к полям структур по указателю
При попытке вывести переменную, содержащую указатель, вы увидите адрес памяти, на который эта переменная указывает.
Как правило, это совсем не то, что вам нужно.
Пример:
package main
import "fmt"
func main() {
var value int = 2 // Создаем значение.
var pointer *int = &value // Получаем указатель на это значение.
fmt.Println(pointer) // Сюрприз! ВЫводится указатель, а не значение!
}
Для получения значения, на которое ссылается указатель, следует воспользоваться оператором *.
Пример:
package main
import "fmt"
func main() {
var value int = 2
var pointer *int = &value
fmt.Println(*pointer) // Выводим значение, на которое ссылается указатель.
}
Казалось бы, оператор * также следует использовать и с указателями на структуры.
Но если вы просто поставите * перед указателем на структуру, такое решение работать не будет:
Пример:
package main
import "fmt"
type myStruct struct {
myField int
}
func main() {
var value myStruct //Создание значения структуры.
value.myField = 3
var pointer *myStruct = &value //Получает указатель на значение структуры.
fmt.Println(*pointer.myField) //Пытаемся получить значение структуры, на которое ссылается указатель.
}
//Ошибка
# command-line-arguments
./18_struct_pointer_bad.go:13:14: invalid indirect of pointer.myField (type int)
Но если вы используете запись *pointer.myField, Go посчитает, что поле myField должно содержать указатель.
В действительности это не так, поэтому происходит ошибка. Чтобы это решение заработало, необходимо заключить *pointer в круглые скобки.
Тогда вы сначала получите значение myStruct, после чего сможете обратиться к полю структуры.
Пример:
package main
import "fmt"
type myStruct struct {
myField int
}
func main() {
var value myStruct
value.myField = 3
var pointer *myStruct = &value
fmt.Println((*pointer).myField) //Получаем значения структуры по указателю, а затем обращаемся к полю структуры.
}
112. Обращение к полям структур по указателю
При попытке вывести переменную, содержащую указатель, вы увидите адрес памяти, на который эта переменная указывает.
Как правило, это совсем не то, что вам нужно.
Пример:
package main
import "fmt"
func main() {
var value int = 2 //Создает значение
var pointer *int = &value //Получает указатель на это значение.
fmt.Println(pointer) //Сюрприз! Выводится указатель, а не значение!
}
#Вывод
0x400011c010
Для получения значения, на которое ссылается указатель, следует воспользоваться оператором *.
Пример:
package main
import "fmt"
func main() {
var value int = 2
var pointer *int = &value
fmt.Println(*pointer)
}
Казалось бы, оператор * также следует использовать и с указателями на структуры.
Но если вы просто поставите * перед указателем на структуру, такое решение работать не будет:
Пример:
package main
import "fmt"
type myStruct struct {
myField int
}
func main() {
var value myStruct //Создание значения структуры.
value.myField = 3
var pointer *myStruct = &value
fmt.Println(*pointer.myField)
}
Ошибка:
# command-line-arguments
./25_struct_pointer.go:13:14: invalid indirect of pointer.myField (type int)
Но если вы используете запись *pointer.myField, Go посчитает, что поле myField должно содержать указатель.
В действительности это не так, поэтому происходит ошибка.
Чтобы это решение заработало, необходимо заключить *pointer в круглые скобки.
Тогда вы сначала получите значение myStruct, после чего сможете обратиться к полю структуры.
Пример:
package main
import "fmt"
type myStruct struct {
myField int
}
func main() {
var value myStruct
value.myField = 3
var pointer *myStruct = &value
fmt.Println((*pointer).myField) //Получаем значения структуры по указателю, а затем обраща-емся к полю структуры.
}
Но каждый раз вводить конструкцию (*pointer).myField быстро надоест.
По этой причине оператор «точка» позволяет обращаться к полям по указателям на структуры точно так же, как вы обращаетесь к полям напрямую по значениям структур.
Круглые скобки и оператор * не обязательны.
Этот способ также работает для присваивания значений полям структур по указателю:
package main
import "fmt"
type myStruct struct {
myField int
}
func main() {
var value myStruct
var pointer *myStruct = &value
pointer.myField = 9
fmt.Println(pointer.myField)
}
Вот так функция applyDiscount может обновлять поле структуры без помощи оператора *.
Происходит присваивание полю структуры по указателю.
package main
import "fmt"
type subscriber struct {
name string
rate float64
active bool
}
func applyDiscount(s *subscriber) {
s.rate = 4.99
}
func main() {
var s subscriber
applyDiscount(&s)
fmt.Println(s.rate)
}
113. Экспорт полей структур
Чтобы имена полей структур экспортировались из своих пакетов, они тоже должны записываться с буквы верхнего регистра.
Пример:
magazine.go
package magazine
type Subscriber struct {
Name string //Верхний регистр.
Rate float64 //Верхний регистр.
Active bool //Верхний регистр.
}
main.go
package main
import (
"fmt"
"package/magazine"
)
func main() {
var s magazine.Subscriber
s.Rate = 4.99 //Верхний регистр
fmt.Println(s.Rate) //Верхний регистр.
}
114. Литералы структур
Код определения структуры и последующего присваивания значений ее полям быстро надоедает:
var subscriber magazine.Subscriber
subscriber.Name = "Aman Singh"
subscriber.Rate = 4.99
subscriber.Active = true
Как и в случае с сегментами и картами, Go предоставляет литералы структур для создания структур одновременно с инициализацией их полей.
Синтаксис имеет много общего с литералами карт. Сначала указывается тип, за ним идут фигурные скобки.
В фигурных скобках можно задать значения полей структуры (всех или некоторых);
для каждого поля указывается имя, двоеточие и значение.
Если вы указываете несколько полей, разделите их запятыми.
Тип структуры.
| Поле. Поле.
| | |
myCar := car{name: "Corvette", topSpeed: 337}
| |
| Значение.
|
Значение.
Выше был приведен код, который создает структуру Subscriber и заполняет ее отдельные поля.
Этот код делает то же самое, что и следующий литерал структуры, состоящий всего из одной строки:
Короткое объявление переменной.
| Литерал для структуры Subscriber.
| | Значение поля Name.
| | | Значение поля Rate
| | | |
subscriber := magazine.Subscriber{Name: "Aman Singh", Rate: 4.99, Active: true}
fmt.Println("Name:", subscriber.Name) |
fmt.Println("Rate:", subscriber.Rate) Значение поля Active.
fmt.Println("Active:", subscriber.Active)
Возможно, вы заметили, что в этой главе нам в основном приходилось использовать длинные объявления для переменных структур (если только структура не возвращалась функцией).
Литералы структур позволяют использовать короткие объявления переменных для только что созданных структур.
Некоторые (и даже все) поля не нужно указывать в фигурных скобках.
Пропущенные поля инициализируются нулевыми значениями для своих типов.
Некоторые (и даже все) поля не нужно указывать в фигурных скобках.
Пропущенные поля инициализируются нулевыми значениями для своих типов.
Поля Name и Active пропущены.
|
subscriber := magazine.Subscriber{Rate: 4.99}
fmt.Println("Name:", subscriber.Name)
fmt.Println("Rate:", subscriber.Rate)
fmt.Println("Active:", subscriber.Active)
115. Промежуточные итоги:
Массивы.
Сегменты.
Карты.
Структуры.
Структура — значение, которое образуется группировкой других значений разных типов.
Отдельные значения, образующие структуру, называются полями.
У каждого поля есть имя и тип.
Определяемые типы.
Определения типов позволяют вам создавать новые типы.
Каждый определяемый тип строится на основе базового типа, который определяет способ хранения значений.
У определяемых типов в качестве базового может использоваться любой тип, хотя чаще всего используются структуры.
Ключевые моменты:
- Переменную можно объявить с типом структуры.
Чтобы задать тип структуры, используйте ключевое слово struct со списком имен полей и типов, заключенным в фигурные скобки.
var myStruct struct {
field1 string
field2 int
}
- Многократно записывать типы структур неудобно, поэтому обычно бывает удобнее определить тип с базовым типом структуры.
После этого определяемый тип может использоваться для переменных, параметров функций, возвращаемых значений и т. д.
type myType struct {
field1 string
}
var myVar myType
- Для обращения к полям структур используется оператор «точка».
myVar.field1 = "value"
fmt.Println(myVar.field1)
- Если структура должна изменяться внутри функции или занимает много памяти, следует передавать ее функции как указатель.
- Чтобы типы экспортировались из пакета, в котором они определяются, их имена должны начинаться с буквы верхнего регистра.
- Так же и поля структур доступны за пределами своего пакета только в том случае, если их имена начинаются с букв верхнего регистра.
- Литералы структур позволяют создать структуру одновременно с инициализацией ее полей.
myVar := myType{field1: "value"}
- При добавлении в структуру поля, у которого нет имени (а есть только тип), определяется анонимное поле.
- Внутренняя структура, добавляемая в составе внешней структуры в виде анонимного поля, называется встроенной.
- К полям встроенной структуры можно обращаться так, словно они принадлежат внешней структуре.
116. Определение методов
Определение метода очень похоже на определение функции.
На самом деле между ними существует только одно отличие:
у метода перед именем функции добавляется один дополнительный параметр, называемый параметром получателя.
Как и в любых параметров функций, необходимо передать имя параметра получателя, за которым следует тип.
Имя параметра получателя.
| Тип параметра получателя.
| |
func (m MyType) sayHi() {
fmt.Println("Hi from", m)
}
Вызов метода, который вы определили, состоит из значения, для которого вызывается метод, точки, имени вызываемого метода и пары круглых скобок.
Значение, для которого вызывается метод, называется получателем метода.
Сходство между вызовами методов и определениями методов поможет вам запомнить синтаксис:
получатель стоит на первом месте при вызове метода, а параметр получателя стоит на первом месте при определении метода.
value := MyType("a MyType value")
value.sayHi()
| |
| Имя метода.
Получатель метода.
Имя параметра получателя в определении метода выбирается произвольно, но важен тип; метод, который вы определяете, связывается со всеми значениями этого типа.
Ниже мы определяем тип с именем MyType, имеющий базовый тип string. Затем определяется метод с именем sayHi.
Так как sayHi имеет параметр получателя с типом MyType, метод sayHi можно будет вызывать для любого значения MyType.
(Многие разработчики скажут, что сам метод sayHi определяется для типа MyType.)
Пример:
package main
import "fmt"
type MyType string //Определяется новый тип
func (m MyType) sayHi() {
fmt.Println("Hi")
}
func main() {
value := MyType("a MyType value") //Создается значение MyType.
value.sayHi() //Вызывается sayHi для этого значения
anotherValue := MyType("another value") //Создается другое значение MyType
anotherValue.sayHi() //Вызывается sayHi для нового значения.
}
После того как метод будет определен для типа, его можно будет вызывать для любого значения этого типа.
В следующем примере мы создаем два разных значения MyType и вызываем sayHi для каждого из них.
Метод (почти) не отличается от функции
Помимо того что методы вызываются для получателя, в остальном они очень похожи на любые другие функции.
Как и в случае с другими функциями, вы можете определять дополнительные параметры в круглых скобках после имени метода.
К этим переменным/параметрам можно обращаться в блоке метода наряду с параметром получателя.
При вызове метода необходимо предоставить аргумент для каждого параметра.
package main
import "fmt"
type MyType string
func (m MyType) MethodWithParameters(number int, flag bool) {
fmt.Println(m)
fmt.Println(number)
fmt.Println(flag)
}
func main() {
value := MyType("MyType value")
value.MethodWithParameters(4, true)
}
Как и в случае с другими функциями, для метода можно объявить одно или несколько возвращаемых значений, которые будут возвращаться при вызове метода:
package main
import "fmt"
type MyType string
func (m MyType) WithReturn() int {
return len(m)
}
func main() {
value := MyType("MyType value")
fmt.Println(value.WithReturn())
}
Как и в случае с любой другой функцией, метод экспортируется из текущего пакета, если его имя начинается с буквы верхнего регистра,
и не экспортируется, если имя начинается с буквы нижнего регистра.
Если вы хотите использовать свой метод за пределами текущего пакета, проследите за тем, чтобы его имя начиналось с буквы верхнего регистра.
Экспортируется — имя начинается с буквы верхнего регистра.
|
func (m MyType) ExportedMethod() {
}
func (m MyType) unexportedMethod() {
} |
Не экспортируется — имя начинается с буквы нижнего регистра.
Вопросы:
В: Могу ли я определять новые методы для любого типа?
О: Только для типов, определяемых в том же пакете, в котором определяется метод.
Это означает, что вы не сможете определять методы для типов из стороннего пакета security, из своего пакета hacking или определять новые методы для таких фундаментальных типов, как int или string.
В: Но мне очень нужно использовать свои методы с чужими типами!
О: Для начала подумайте, не подойдет ли для этого функция, ведь функции могут получать любые типы в параметрах.
Но если вам действительно необходимо значение, которое имеет собственные методы, а также некоторые методы типа из другого пакета, создайте тип структуры,
в котором тип из другого пакета встроен как анонимное поле.
В: Я видел другие языки, в которых получатель метода был доступен в блоке метода в виде специальной переменной с именем self или this.
А как дело обстоит в Go?
О: Go использует параметры получателей вместо self и this.
Принципиальное отличие заключается в том, что self и this задаются неявно, тогда как параметр получателя объявляется явно.
В остальном параметры получателей работают точно так же, а языку Go не нужно резервировать self или this как ключевые слова!
(Вы даже сможете присвоить параметру получателя имя this, но делать так не стоит:
по общепринятым соглашениям вместо этого используется первая буква имени типа.)
Go позволяет присвоить параметру получателя любое имя, но код будет лучше читаться, если все методы,
определяемые для типа, имеют параметры получателей с одинаковыми именами.
По общепринятым соглашениям разработчики Go обычно используют имя, состоящее из одной буквы — первой буквы имени типа получателя в нижнем регистре.
(Именно поэтому мы использовали m как имя параметра получателя MyType.)
Метод почти не отличается от функции
Помимо того что методы вызываются для получателя, в остальном они очень похожи на любые другие функции.
Как и в случае с другими функциями, вы можете определять дополнительные параметры в круглых скобках после имени метода.
К этим переменным/параметрам можно обращаться в блоке метода наряду с параметром получателя.
При вызове метода необходимо предоставить аргумент для каждого параметра.
117. Будьте осторожны!
Чтобы вызвать метод, которому требуется получатель-указатель, необходимо иметь возможность получить указатель на значение!
Вы можете получать указатели только на значения, хранящиеся в переменных.
При попытке получить адрес значения, не хранящегося в переменной, вы получите сообщение об ошибке:
&MyType("a value")
Ошибка.
cannot take the address of MyType("a value")
То же ограничение действует при вызове методов с получателями-указателями.
Go может автоматически преобразовать значения в указатели, но только если значение указателя хранится в переменной.
При попытке вызвать метод для самого значения Go не сможет получить указатель, и вы получите похожую ошибку:
MyType("a value").pointerMethod()
Ошибки.
cannot call pointer method
on MyType("a value")
cannot take the address
of MyType("a value")
Вместо этого нужно сохранить значение в переменной;
это позволит Go получить указатель на нее:
value := MyType("a value")
value.pointerMethod() //Go преобразует значение в указатель.
118. Сломай и изучи!
Перед вами уже знакомый тип Number с определениями пары методов.
Внесите одно из указанных изменений и запустите программу;
затем отмените изменение и переходите к следующему.
Посмотрите, что из этого выйдет!
#0 Пример кода:
package main
import "fmt"
type Number int
func (n *Number) Display() {
fmt.Println(*n)
}
func (n *Number) Double() {
*n *= 2
}
func main() {
number := Number(4)
number.Double()
number.Display()
}
#1 Заменить тип параметра получателя типом, не определенным в текущем пакете:
func (n *Numberint) Double() {
*n *= 2
}
Ошибка:
# command-line-arguments
./22_type_method.go:7:6: cannot define new methods on non-local type int
./22_type_method.go:18:8: number.Display undefined (type Number has no field or method Display)
Программа не будет работать, потому что:
Новые методы могут определяться только для типов, объявленных в текущем пакете.
Определение метода для глобально определяемого типа (такого, как int) приведет к ошибке компиляции.
#2 Заменить тип параметра получателя Double типом, который не является указателем:
func (n *Number) Double() {
*n *= 2
}
Ошибка:
работает не правильно
Программа не будет работать, потому что:
Параметры получателей получают копию значения, для которого был вызван метод.
Если функция Double изменит только копию, то исходное значение останется неизменным при выходе из Double.
#3 Вызвать метод, которому необходим получатель-указатель, для значения, которое не хранится в переменной:
Number(4).Double()
Ошибка:
# command-line-arguments
./24_type_method.go:19:11: cannot call pointer method on Number(4)
./24_type_method.go:19:11: cannot take the address of Number(4)
Программа не будет работать, потому что:
При вызове метода с получателем, который является указателем,
Go может автоматически преобразовать значение в указатель на получателя,
если он хранится в переменной.
В противном случае произойдет ошибка
#4 Заменить тип параметра получателя Display типом, который не является указателем:
func (n *Number) Display() {
fmt.Println(*n)
}
Ошибка:
Нарушает общепринятые соглашения! :(
Программа не будет работать, потому что:
На самом деле после внесения этого изменения код будет работать, но нарушит общепринятые соглашения!
Параметры получателей в методах типа могут быть либо указателями, либо значениями, и смешивать их не рекомендуется
119. Преобразование литров и миллилитров в галлоны с помощью методов
package main
import "fmt"
type Liters float64
type Milliliters float64
type Gallons float64
func (l Liters) ToGallons() Gallons {
return Gallons(1 * 0.264) //Блок метода не отличается от блока функции
}
func (m Milliliters) ToGallons() Gallons { //Имена могут быть одинаковыми, если они определяются для разных типов
return Gallons(m * 0.000264) //Блок метода не отличается от блока функции
}
func main() {
soda := Liters(2) //Создание Liters
fmt.Printf("%0.3f litters equals %0.3f gallonsn", soda, soda.ToGallons())
water := Milliliters(500) // Создание значения Milliliters
fmt.Printf("%0.3f milliliters equals %0.3f gallonsn", water, water.ToGallons()) //Преобразование Milliliters в Gallons
}
120. Ключевые моменты
Определяемые типы:
Определение типов позволяют вам создавать собственные типы.
Каждый определяемый тип основывается на базовом типе, который определяет формат хранения значений.
Определение методов:
Определение метода не отличается от определения функции, помимо того, что в него включается параметр получателя.
Метод связывается с типом параметра получателя.
В дальнейшем этот метод может вызываться для любых значений этого типа.
- После того как тип будет определен, вы можете выполнить преобразование к нему любого значения того же базового типа:
Gallons(10.0)
- После определения типа переменной значения других типов не могут присваиваться этой переменной, даже если они имеют тот же базовый тип.
- Определяемый тип поддерживает все те же операторы, что и базовый тип.
Например, тип, основывающийся на базовом типе int, будет поддерживать операторы +, -, *, /, ==, > и <.
- Определяемый тип может использоваться в операциях совместно со значениями-литералами:
Gallons(10.0) + 2.3
- Чтобы определить метод, укажите параметр получателя в круглых скобках перед именем метода:
func (m MyType) MyMethod() {
}
- Параметр получателя может использоваться в блоке метода, как любой другой параметр:
func (m MyType) MyMethod() {
fmt.Println("called on", m)
}
- Для методов, как и для любых других функций, можно определять дополнительные параметры или возвращаемые значения.
- Определение нескольких одноименных функций в одном пакете запрещено, даже если они имеют параметры разных типов.
С другой стороны, вы можете определить несколько методов с одинаковыми именами при условии,
что они определяются для разных типов.
- Методы могут определяться только для типов, определенных в том же пакете.
- Как и для других параметров, в параметрах получателей передается копия исходного значения.
Если ваш метод должен изменять получатель, используйте тип указателя для параметра получателя и измените значение по этому указателю.
120. Инкапсуляция и встраивание / Set-метод
Тип структуры — всего лишь разновидность определяемого типа;
это означает, что для него, как и для любых других определяемых типов, могут определяться методы.
Попробуем создать для типа Date методы SetYear, SetMonth и SetDay, которые получают значение, проверяют его,
и если значение допустимо — присваивают его соответствующему полю структуры.
Такие методы часто называются set-методами, или сеттерами.
По общепринятым соглашениям set-методам в Go присваиваются имена в форме SetX, где X — присваиваемое поле.
121. Get-методы
Как вы уже знаете, методы, предназначенные для присваивания значения поля структуры или переменной, называются set-методами.
Как и следовало ожидать, методы, предназначенные для получения значения поля структуры или переменной, называются get-методами, или геттерами.
По сравнению с set-методами добавить get-методы в тип Date будет проще.
При вызове им не нужно ничего делать, кроме как вернуть значение поля.
По общепринятым соглашениям имя get-метода должно совпадать с именем поля или переменной, к которой он обращается.
(Конечно, чтобы метод экспортировался, его имя должно начинаться с буквы верхнего регистра.)
Таким образом, типу Date понадобится метод Year для обращения к полю year, метод Month для обращения к полю month, а метод Day для поля day.
Get-методам вообще не нужно изменять получателя, поэтому в качестве получателя можно было использовать непосредственное значение Date.
Но если любой метод типа получает указатель на получателя, согласно общепринятым соглашениям все методы должны получать указатель для предотвращения путаницы.
Так как set-методы используют указатель на получателя, get-методы тоже должны использовать указатель.
После внесения всех изменений в date.go обновим файл main.go: сначала он задает значения всех полей Date, а затем выводит их при помощи get-методов.
Пример кода date.go
package calendar
import "errors"
type Date struct {
year int
month int
day int
}
func (d *Date) Year() int {
return d.year
}
func (d *Date) Month() int {
return d.month
}
func (d *Date) Day() int {
return d.day
}
// Set-методы пропущены
Пример кода main.go
// Директивы package и import пропущены
func main() {
date := calendar.Date{}
err := date.SetYear(2019)
if err != nil {
log.Fatal(err)
}
err = date.SetMonth(5)
if err != nil {
log.Fatal(err)
}
err = date.SetDay(27)
if err != nil {
log.Fatal(err)
}
fmt.Println(date.Year())
fmt.Println(date.Month())
fmt.Println(date.Day())
}
121. Инкапсуляция
Практика сокрытия данных в одной части программы от кода в другой части называется инкапсуляцией.
Механизм инкапсуляции поддерживается не только в Go. Инкапсуляция полезна прежде всего тем, что помогает защититься от некорректных данных (как вы уже видели).
Кроме того, разработчик может изменять инкапсулированную часть программы, не рискуя нарушить работоспособность другого кода,
который обращается к этой части из-за возможности прямого доступа.
Многие другие языки программирования инкапсулируют данные в классах.
(На концептуальном уровне классы похожи на типы Go, но не идентичны им.)
В Go данные инкапсулируются в пакетах с применением не экспортируемых переменных, полей структур, функций или методов.
В других языках инкапсуляция применяется намного чаще, чем в Go.
Например, в некоторых языках принято определять get- и set-методы для каждого поля, даже если к нему можно обратиться напрямую.
Разработчики обычно применяют инкапсуляцию только при необходимости — например, когда требуется проверить данные поля set-методами.
В языке Go, если вы не видите явной необходимости в инкапсуляции поля,
обычно бывает проще экспортировать это поле и предоставить прямой доступ к нему.
Вопросы:
В: Многие другие языки не разрешают обращаться к инкапсулированным значениями за пределами класса, в котором они определяются.
Go разрешает другому коду из того же пакета обращаться к не экспортируемым полям.
Насколько это безопасно?
О: Как правило, весь код пакета пишется одним разработчиком (или группой разработчиков).
Кроме того, весь код пакета обычно предназначен для одной цели.
Скорее всего, авторам кода из пакета потребуется доступ к не экспортируемым данным, поэтому с большой вероятностью они будут работать с этими данными корректно.
Таким образом, взаимодействие остального кода пакета с не экспортированными данными обычно безопасно.
С другой стороны, код за пределами пакета с большой вероятностью будет написан другими разработчиками,
но это нормально — ведь не экспортированные поля скрыты от них, и они не могут случайно изменить их недействительными значениями.
В: Я видел другие языки, в которых имена всех get-методов начинаются с префикса «Get» — например, GetName, GetCity и т. д.
А в Go это возможно?
О: Язык Go позволит вам это сделать, но так поступать не стоит.
Сообщество Go выработало соглашения, по которым префикс Get не указывается в именах get-методов.
Включение префикса только запутает ваших коллег-разработчиков!
Для set-методов в Go используется префикс Set, как и во многих других языках,
потому что позволяет отличить set-методы от get-методов для того же поля.
Инкапсуляция — практика сокрытия данных в одной части программы от кода в другой части.
Инкапсуляция может использоваться для защиты от недействительных данных.
Инкапсулированные данные проще изменять.
Вы можете быть уверены в том, что это не нарушит работоспособности кода, обращающегося к этим данным.
Встраивание
Тип, хранимый в типе структуры с использованием анонимного поля, называется встроенным в структуру.
Методы встроенного типа повышаются до внешнего типа.
Они могут вызываться так, как если бы были определены для внешнего типа.
Ключевые моменты:
- В Go данные инкапсулируются в пакетах с помощью не экспортированных переменных пакетов или полей структур.
- К не экспортированным переменным, полям структур, функциям, методам и т. д. можно обращаться из экспортируемых функций и методов, определенных в том же пакете.
- Практика проверки действительности данных перед их сохранением называется проверкой данных.
- Метод, используемый в основном для задания значения не инкапсулируемого поля, называется set-методом.
Set-методы часто включают логику проверки данных, которая гарантирует, что присваиваемое значение будет допустимым.
- Так как set-методы должны изменять своего получателя, их параметр получателя должен иметь тип указателя.
- Традиционно set-методам присваиваются имена вида SetX, где X — имя присваиваемого поля.
- Метод, предназначенный для получения значения инкапсулированного поля, называется get-методом.
- Имена get-методов традиционно задаются в форме X, где X — имя поля.
В некоторых других языках программирования для get-методов была выбрана форма GetX, но в Go эту форму использовать не рекомендуется.
- Методы, определяемые для внешнего типа структуры, существуют на одном уровне с методами, повышенными от встроенного типа.
- Не экспортируемые методы встроенного типа не повышаются до уровня внешнего типа.
122. Интерфейсы
Иногда конкретный тип значения не важен.
Вас не интересует, с чем вы работаете.
Вы просто хотите быть уверены в том, что оно может делать то, что нужно вам.
Тогда вы сможете вызывать для значения определенные методы.
Неважно, с каким значением вы работаете — Pen или Pencil; вам просто нужно нечто, содержащее метод Draw.
Именно эту задачу решают интерфейсы в языке Go. Они позволяют определять переменные и параметры функций,
которые могут хранить любой тип при условии, что этот тип определяет некоторые методы.
Помните кассетные магнитофоны? (Хотя, наверное, некоторые читатели их уже не застали.) Это были полезные устройства.
Они позволяли легко записать на пленку все ваши любимые песни — даже созданные разными исполнителями.
Конечно, магнитофоны были слишком громоздкими, чтобы постоянно носить их с собой.
Если вам хотелось взять кассеты в дорогу, обычно для этого использовались плееры на батарейках.
Плееры обычно не поддерживали возможности записи.
Ах, как же это было здорово — создавать собственные миксы и обмениваться ими с друзьями!
Ностальгия так захватила нас, что мы создали пакет gadget для оживления воспоминаний.
В него входит тип TapeRecorder, представляющий кассетный магнитофон, и тип TapePlayer, представляющий плеер.
Ошибки:
# command-line-arguments
./04_gadget.err.go:40:10: cannot use player (type TapeRecorder) as type TapePlayer in argument to playList
Когда вы устанавливаете программу на свой компьютер, разумно ожидать, что эта программа предоставит какие-то средства для взаимодействия с ней.
Текстовый редактор предоставит место для ввода текста. Программа архивации — возможность выбрать сохраняемые файлы.
В электронной таблице есть инструменты для вставки столбцов и строк данных. Набор средств, предоставляемых программой для взаимодействия с ней, часто называется ее интерфейсом.
Задумывались вы об этом или нет, можно ожидать, что значения Go тоже предоставят средства для взаимодействия с ними.
Как вы чаще всего взаимодействуете со значениями Go? Пожалуй, через их методы.
В Go интерфейс определяется как набор методов, которые должны поддерживаться некоторыми значениями.
Таким образом, интерфейс представляет набор действий, выполняемых с использованием типа.
Определение типа интерфейса состоит из ключевого слова interface, за ним следуют фигурные скобки со списком имен методов,
а также параметрами и возвращаемыми значениями, которые должны иметь эти методы.
Интерфейс — набор методов, который должен поддерживаться некоторыми значениями.
Ключевое слово interface
|
type myInterface interface {
methodWithoutParameters() //Имя метода
methodWithParameter(float64) //Имя метода //Тип параметра
methodWithReturnValue() string //Имя метода
} |
Тип возвращаемого значения.
Любой тип, который содержит все методы, перечисленные в определении интерфейса, называется поддерживающим этот интерфейс.
Тип, поддерживающий интерфейс, может использоваться в любом месте, где должен использоваться этот интерфейс.
Имена методов, типы параметров (если они есть) и типы возвращаемых значений (если они есть) должны совпадать с определениями в интерфейсе.
Тип может содержать методы помимо тех, которые перечислены в интерфейсе, но в нем не могут отсутствовать такие методы, иначе тип не будет поддерживать интерфейс.
Тип может поддерживать несколько интерфейсов, а интерфейс может (и обычно должен) поддерживаться несколькими типами.
122. Интерфейсы, cломай и изучи!
Пример кода:
package main
import "fmt"
type Appliance interface {
TurnOn()
}
type Fan string
func (f Fan) TurnOn() {
fmt.Println("Spinning")
}
type CoffeePot string
func (c CoffeePot) TurnOn() {
fmt.Println("Powering up")
}
func (c CoffeePot) Brew() {
fmt.Println("Heating Up")
}
func main() {
var device Appliance
device = Fan("Windco Breeze")
device.TurnOn()
device = CoffeePot("LuxBrew")
device.TurnOn()
}
Вывод:
Spinning
Powering up
Приступаем ломать:
#1 Вызвать метод конкретного типа, не определенный в интерфейсе:
device.Brew()
Ошибка:
# command-line-arguments
./08_dz.go:28:8: device.Brew undefined (type Appliance has no field or method Brew)
Почему ошибка:
Если в переменной с типом интерфейса хранится значение, вызывать можно только методы,
определенные как часть интерфейса, независимо от того, какие методы содержит реальный тип.
#2 Удалить из типа метод, обеспечивающий поддержку интерфейса:
func (c CoffeePot) TurnOn() {
fmt.Println("Powering up")
}
Ошибка:
# command-line-arguments
./09_dz.go:23:9: cannot use CoffeePot("LuxBrew") (type CoffeePot) as type Appliance in assignment:
CoffeePot does not implement Appliance (missing TurnOn method)
Почему ошибка:
Если тип не поддерживает интерфейс, значения этого типа не могут присваиваться переменным, объявленным с типом этого интерфейса
#3 Добавить новое возвращаемое значение или параметр в метод, обеспечивающий поддержку интерфейса:
func (f Fan) TurnOn() error {
fmt.Println("Spinning")
return nil
}
Ошибка:
# command-line-arguments
./10_dz.go:23:6: method redeclared: Fan.TurnOn
method(Fan) func()
method(Fan) func() error
./10_dz.go:23:14: Fan.TurnOn redeclared in this block
previous declaration at ./10_dz.go:10:6
Почему ошибка:
Если количество и типы всех параметров и возвращаемых значений не соответствуют определению метода конкретного типа и определению метода в интерфейсе,
то конкретный тип не поддерживает интерфейс.
123. Ключевые моменты Интерфейсы:
Интерфейс — набор методов, которые должны поддерживаться некоторыми значениями.
Любой тип, который содержит все методы, перечисленные в определении интерфейса, поддерживает этот интерфейс.
Тип, поддерживающий интерфейс, может быть присвоен любой переменной или параметру функции, которые объявлены с типом этого интерфейса.
- Конкретный тип указывает не только то, что могут делать значения (какие методы для них можно вызывать),
но и то, чем они являются: он задает базовый тип, в котором хранятся данные значения.
- Тип интерфейса — абстрактный тип.
Интерфейсы не описывают, чем является значение:
они ничего не говорят о том, какой базовый тип используется или как хранятся его данные.
Они описывают только то, что значение может делать: какие методы оно содержит.
- Определение интерфейса должно содержать список имен методов со всеми параметрами или возвращаемыми значениями, которые должны иметь такие методы.
- Чтобы поддерживать интерфейс, тип должен содержать все методы, заданные в интерфейсе.
Имена методов, типы параметров (если они есть) и типы возвращаемых значений (если они есть) должны совпадать с теми, которые определены в интерфейсе.
- Тип может содержать методы помимо тех, которые перечислены в интерфейсе, но никакие из обязательных методов не могут отсутствовать;
в противном случае тип не поддерживает интерфейс.
- Тип может поддерживать сразу несколько интерфейсов, и интерфейс может поддерживаться сразу несколькими типами.
- Поддержка интерфейсов достигается автоматически.
В Go не нужно специально объявлять, что конкретный тип поддерживает интерфейс.
- Для переменной с типом интерфейса можно вызывать только те методы, которые определены в интерфейсе.
- Если значение конкретного типа присвоено переменной с типом интерфейса, вы можете воспользоваться
утверждением типа для получения значения конкретного типа.
Только после этого вы сможете вызывать методы, определенные для конкретного типа (но не для интерфейса).
- Утверждения типов возвращают второе логическое значение, которое сообщает, успешно ли было выполнено утверждение.
car, ok := vehicle.(Car)
124. Восстановление после сбоев