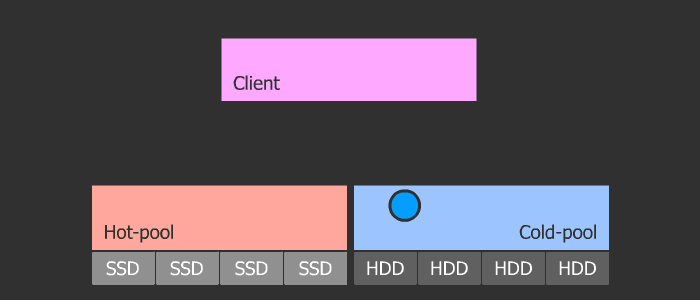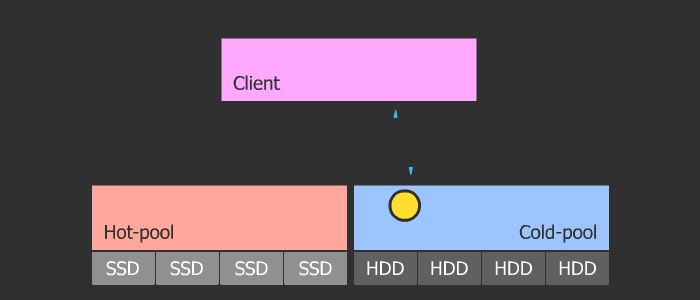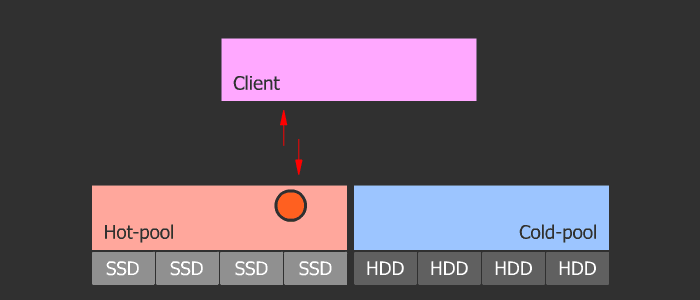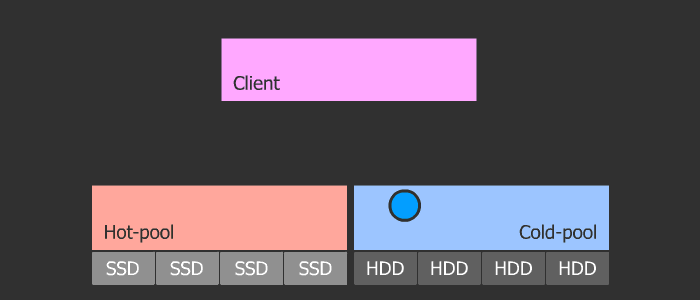
Использовал материал:
https://docs.ceph.com/docs/master/install/ceph-deploy/quick-start-preflight/#debian-ubuntu https://docs.ceph.com/docs/hammer/rados/configuration/ceph-conf/ https://ceph.io/planet/installing-ceph-the-easy-peasy-way/ https://ceph.io/planet/hosting-a-web-site-in-radosgw/ https://habr.com/ru/post/313644/ https://habr.com/ru/post/315646/ https://habr.com/ru/company/oleg-bunin/blog/431536/ https://habr.com/ru/company/croccloudteam/blog/422905/ https://habr.com/ru/post/179823/ https://habr.com/ru/post/180415/ https://www.facebook.com/notes/hosterby/%D0%BE%D0%BF%D1%8B%D1%82-%D0%B2%D0%BD%D0%B5%D0%B4%D1%80%D0%B5%D0%BD%D0%B8%D1%8F-%D0%B8-%D1%8D%D0%BA%D1%81%D0%BF%D0%BB%D1%83%D0%B0%D1%82%D0%B0%D1%86%D0%B8%D0%B8-ceph/1931973293570283/ https://cloud.yandex.ru/docs/storage/tools/s3cmd - случано нашел прикольную инструкцию на русском +) https://stackoverflow.com/questions/45012905/removing-pool-mon-allow-pool-delete-config-option-to-true-before-you-can-destro - удаление пула https://xakep.ru/2010/08/12/52949/ - s3cmd
Дано:
дистрибутив у нас lsb_release -a No LSB modules are available. Distributor ID: Ubuntu Description: Ubuntu 18.04.5 LTS Release: 18.04 Codename: bionic Три виртуальные машины с ip 10.0.0.4 10.0.0.5 10.0.0.6
Нужно сделать:
а) Необходимо создать кластер из трех нод с последней версией ceph б) создать pool в) создать s3 bucket г) ceph -s - должен HEALTH_OK д) положить в него что угодно (картинку, файл) и предоставить ссылку на его скачивание без пароля Ну собственно что мы будем делать: Подымем ceph; ceph -s - покажит HEALTH_OK; подымим pool; на одной из нод настроим rgw; добавим в pool файл с помощью s3cmd; установим haproxy и натравим его на rgw; собственно подключимся по ip:80/bucket/filename и получим наш файл...
0. Обновим ос
sudo su apt update sudo dpkg --configure -a apt update apt upgrade
1. Переименуем хосты
sudo nano /etc/cloud/cloud.cfg - и установить параметр "preserve_hostname" с false на true sudo hostnamectl set-hostname nod0.inc sudo hostnamectl set-hostname nod1.inc sudo hostnamectl set-hostname nod2.inc
2. DNS записи
Пожалуй просто добавим ip нод в /etc/hosts на всех нодах nano /etc/hosts 10.0.0.4 nod0.inc 10.0.0.5 nod1.inc 10.0.0.6 nod2.inc
3. Зададим пароль root
Ceph нужен root на нодах... Задаем пароль root на всех нодах sudo su passwd
4. Разрешим подключаться root по ssh :(
Ceph нужен доступ root по ssh. добавил на все серверы nano /etc/ssh/sshd_config добавим строку PermitRootLogin yes
5. Необходимо генерировать сертификаты пользователю root для ssh на всех нодах:
Необходимо генерировать сертификаты пользователю root для ssh на всех нодах nod0,nod1,nod2 и скопируем их на другие ноды sudo su ssh-keygen ssh-copy-id root@nod0.inc ssh-copy-id root@nod1.inc ssh-copy-id root@nod2.inc
6. Синхронизация времени
Для избежания проблем связанных со временем нужно установил пакеты синхронизации времени на все ноды apt install ntp -y
7. Перезагрузим ноды
sudo reboot
8. Добавим репозиторий ceph на все ноды
ключи:
#wget -q -O- 'https://download.ceph.com/keys/release.asc' | sudo apt-key add -
репозиторий:
#список релизовhttps://docs.ceph.com/docs/master/releases/
#!!! вот тут внимание в строке ниже {ceph-stable-release} меняем на желаемую версию CEPH
# echo deb https://download.ceph.com/debian-{ceph-stable-release}/ $(lsb_release -sc) main | sudo tee /etc/apt/sources.list.d/ceph.list
# пример nautilus echo deb https://download.ceph.com/debian-nautilus/ $(lsb_release -sc) main | sudo tee /etc/apt/sources.list.d/ceph.list
# В моем случае я буду ставить последнию Octopus на данный момент из https://docs.ceph.com/docs/master/releases/
# вот такая у меня будет строка echo deb https://download.ceph.com/debian-octopus/ $(lsb_release -sc) main | sudo tee /etc/apt/sources.list.d/ceph.list
Добавляем ключи репа и репозиторий:
wget -q -O- 'https://download.ceph.com/keys/release.asc' | sudo apt-key add -
echo deb https://download.ceph.com/debian-octopus/ $(lsb_release -sc) main | sudo tee /etc/apt/sources.list.d/ceph.list
Проверим что все ок
apt update
9. Пред установим на все ноды ceph-deploy
apt install python-minimal # в документации просили поставить apt install ceph-deploy -y
10. теперь самое главное, ради чего мы тут собрались:
Идем на сервер nod0, Заходим под root sudo su Создадим каталог туда будут складыватся конфиги и т.д. mkdir /etc/ceph Зайдем в него cd /etc/ceph Создаем новый кластер ceph-deploy new nod0.inc nod1.inc nod2.inc Устанавливаем дистрибутив Ceph на машины ceph-deploy install nod0.inc nod1.inc nod2.inc Создаем мониторы, указанные при создании кластера ceph-deploy mon create-initial # доставить мониторы ceph-deploy mgr create nod0.inc nod1.inc nod2.inc ceph-deploy mds create nod0.inc nod1.inc nod2.inc
11. Готовим диски
Смотрим что у нас там есть за диски
fdisk -l
в моем случаем на каждой ноде есть по одному диску sdb
####ceph-deploy disk zap {cn1,cn2,cn3}:{sdb,sdc,sdd}
####ceph-deploy disk zap cn1:sdb cn1:sdc cn1:sdd cn2:sdb cn2:sdc cn2:sdd cn3:sdb cn3:sdc cn3:sdd
####ceph-deploy osd create {cn1,cn2,cn3}:{sdb,sdc,sdd}
#Очищаем и готовим диски к добавлению в кластер
#ceph-deploy disk zap {nod0.inc,nod1.inc,nod2.inc}:{sdb}
#!!!!
# Я хз у меня перестало так работать при использовании масок {cn1,cn2,cn3}:{sdb,sdc,sdd}
#Ошибки
#ssh: Could not resolve hostname nod0:sdb: Temporary failure in name resolution
#[ceph_deploy][ERROR ] RuntimeError: connecting to host: nod0:sdb resulted in errors: HostNotFound nod0:sdb
# даже имя пк к FQDN привел... Пос ssh подключается, пингуется и т.д
#выполнил так
ceph-deploy disk zap nod0.inc /dev/sdb
ceph-deploy disk zap nod1.inc /dev/sdb
ceph-deploy disk zap nod2.inc /dev/sdb
Превращаем диски в OSD и создаем соответствующие демоны
# и вот так больше не работает..... чднт?
#ceph-deploy osd create nod0.inc:sdb nod1.inc:sdb nod2.inc:sdb
# ну ок из инструкции.... https://docs.ceph.com/docs/master/install/ceph-deploy/quick-ceph-deploy/
ceph-deploy osd create --data /dev/sdb nod0.inc
ceph-deploy osd create --data /dev/vdb nod0.inc
ceph-deploy osd create --data /dev/vdb nod0.inc
Проверяем:
root@nod0:/etc/ceph# ceph -s
cluster:
id: 103840c7-2115-4b20-839b-60bed7446aba
health: HEALTH_WARN
no active mgr
services:
mon: 3 daemons, quorum nod0,nod1,nod2
mgr: no daemons active
osd: 3 osds: 3 up, 3 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs:
Ожидание:
Проверяем его состояние командой ceph -s или ceph status
Ключевая строка в этом отчете — это health, и оно находится в состоянии HEALTH_WARN.
Это лучше, чем HEALTH_ERR, потому что так у нас хотя бы кластер работает, хотя и не очень.
А сразу под HEALTH_WARN написано, почему же оно _WARN, а именно: «too few PGs per OSD (21 < min 30)»,
что говорит нам о необходимости увеличить количество плейсмент-групп так, чтобы на один OSD приходилось минимум 21 PG.
Тогда умножаем 9 OSD на 21 и получаем 189, затем округляем до ближайшей степени двойки и получаем 256.
В то время как текущее количество PG=64, что ясно видно в строке pgmap. Все это описано в документации Ceph. https://docs.ceph.com/docs/master/
Видим две проблемы:
health: HEALTH_WARN
no active mgr
mgr: no daemons active
И еще:
ceph health
HEALTH_WARN no active mgr
12. Добавляем менеджеров....
ceph-deploy mgr create nod0.inc nod1.inc nod2.inc
Проверяем:
ceph health
HEALTH_OK
Еще:
root@nod0:/etc/ceph# ceph health
HEALTH_OK
root@nod0:/etc/ceph# ceph -s
cluster:
id: 103840c7-2115-4b20-839b-60bed7446aba
health: HEALTH_OK
services:
mon: 3 daemons, quorum nod0,nod1,nod2
mgr: nod0.inc(active), standbys: nod1.inc, nod2.inc
osd: 3 osds: 3 up, 3 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 3.0 GiB used, 63 GiB / 66 GiB avail
pgs:
13. Ceph tool
ceph osd tree - посмотреть состояние дисков
ceph -s - посмотреть состояне ceph
ceph quorum_status --format json-pretty - еще одна проверка
ntpdate ru.pool.ntp.org - синхронизация времени может пригодится ...
ceph osd pool stats [{pool-name}] - посмотреть статус пулов
ceph osd pool stats - посмотреть статус пулов
sudo ceph osd lspools - посмотреть пулы
ceph -w - проверить работа способность кластера
ceph mon dump - проверить состояние кворума монитора Ceph
ceph df - проверьте состояние применения кластера
ceph osd lspools - вывести список ваших пулов Ceph
ceph osd tree - просмотреть карту CRUSH OSD
ceph-authtool --name client.admin /etc/ceph/ceph.client.admin.keyring --print-key - показать ключ админа
ceph-authtool --name client.admin /etc/ceph/ceph.client.admin.keyring --print-key | tee /etc/ceph/admin.secret - показать ключ админа и сохронить в файл /etc/ceph/admin.secret
Проконтролировать статистику ваших мониторов, OSD и групп размещения Ceph:
# ceph mon stat
# ceph osd stat
# ceph pg stat
PG-NUM
PGP это группы размещения для целей расположения (Placement Group for Placement purpose), которое должно оставаться равным общему числу групп размещения (pg_num).
Если вы увеличивает число групп размещения для пула Ceph, то есть pg_num, то вы должны также увеличить pgp_num до того же целочисленного значения, равного pg_num,
следовательно кластер начнет процесс ребалансировки.
Скрытый механизм ребалансировки можно пояснить следующим образом.
Значение pg_num определяет число групп размещения, которое отображается на OSD (устройства хранения объектов).
Когда значение pg_num увеличивается для любого пула, каждая PG этого пула разделяется пополам, однако они все по прежнему отображаются на свои родительские OSD.
До этого момента времени Ceph не начинает ребалансировку.
Теперь, когда вы увеличиваете значение pgp_num для того же самого пула, PG начинают миграцию с родительских на некоторые другие OSD и начинается ребалансировка.
Таким образом, PGP играет важную роль в ребалансировке кластера.
####.Расчет общего количества групп размещения.
(OSD * 100)
Всего PG = ------------
размер бассейна
Например, предположим, что в вашем кластере 9 OSD, а размер пула по умолчанию равен 3. Таким образом, ваши PG будут
9 * 100
Всего PG = ------------ = 300
14. Создаем pool / где то надо данные то хранить =)
Pool создается в два действия.
Первое действие его нужно создать.
Второе действие его нужно привязать к приложению.
У нас три варианта pool. RDB, RGW, CEPHFS.
RDB - блочные устройства \ диски для виртуалок и тд
RGW - доступ по http \ S3
СEPHFS - без комментариев...
RADOS
Создаем pool
# Как правильно считать pg-num я не знаю, смотрите документацию ceph, так же у этой опции есть autoscaling....
#ceph osd pool create {pool-name} {pg-num}
ceph osd pool create img 100 - создали pool с именем img и pg-num=100
#Перед использованием пулы должны быть связаны с приложением.
#Пулы, которые будут использоваться с CephFS, или пулы, автоматически созданные RGW, автоматически связываются.
#--- Ceph Filesystem ---
#$ sudo ceph osd pool application enable cephfs
#--- Ceph Block Device ---
#$ sudo ceph osd pool application enable rbd
#--- Ceph Object Gateway ---
# $ sudo ceph osd pool application enable rgw
#Пример:
#$ sudo ceph osd pool application enable k8s-uat-rbd rbd
#enabled application 'rbd' on pool 'k8s-uat-rbd'
#Пулы, предназначенные для использования с RBD, следует инициализировать с помощью rbd инструмента:
#sudo rbd pool init k8s-uat-rbd
#Чтобы отключить приложение, используйте:
#ceph osd pool application disable {--yes-i-really-mean-it}
#Чтобы получить информацию о вводе-выводе для определенного пула или всего, выполните:
#$ sudo ceph osd pool stats [{pool-name}]
#Пулы, предназначенные для использования с RBD, должны быть инициализированы с использованием инструмента rbd:
#sudo rbd pool init k8s-uat-rbd
sudo ceph osd pool application enable img rgw - Связали пул img с приложением RGW
15. RGW (Ceph Object Gateway)
ceph-deploy rgw create nod0.inc #Порт RGW по умолчанию 7480. #Его можно изменить в файле ceph.conf (на ноде откуда запустили) ---ceph.conf--- [client] rgw frontends = civetweb port=80 ---------------
15.1 Пример из документации создание pool RGW, добавление данных и удаление pool
Хранение объектов с применением шлюза Ceph RADOS radosgw-admin radosgw-admin --help # Тест из docs ceph osd pool create mytest 10 rados put test-object-1 testfile.txt --pool=mytest rados -p mytest ls ceph osd map mytest test-object-1 rados rm test-object-1 --pool=mytest ceph osd pool rm mytest ceph osd pool rm mytest --yes-i-really-really-mean-it ceph osd pool rm mytest mytest --yes-i-really-really-mean-it
15.2 Удаление pool / пуллов
Удаление пула происходит в несколько шагов. Сначала надо отключить аппликацию этого пула. После отключения его можно будет удалить. В теории достаточно трех команд ниже: ceph osd pool application disable{--yes-i-really-mean-it} sudo ceph osd pool stats [{pool-name}] sudo ceph osd pool delete {pool-name} [{pool-name} --yes-i-really-really-mean-it] Но на практике удаление еще нужно разрешить... ceph osd lspools - выведет список пулов ceph osd pool application disable ЧТО_ХОТИМ_УДАЛИТЬ cephfs --yes-i-really-mean-it - отключаем pool ceph osd pool delete ЧТО_ХОТИМ_УДАЛИТЬ ЧТО_ХОТИМ_УДАЛИТЬ --yes-i-really-really-mean-it - удаление пула :) ceph tell mon.\* injectargs '--mon-allow-pool-delete=true' - задаем параметр для возможности удаления пулов !!! ceph config set mon mon_allow_pool_delete true - аналогичная cli команда, задаем параметр для возможности удаления пулов ceph osd pool delete ЧТО_ХОТИМ_УДАЛИТЬ ЧТО_ХОТИМ_УДАЛИТЬ --yes-i-really-really-mean-it - вот теперь точно удалим (!!! два раза требует команда удаления ЧТО_ХОТИМ_УДАЛИТЬ)
16. монтирование CephFS
apt-get install ceph-fuse - ставим
Создайте каталог точки монтирования:
# mkdir /mnt/kernel_cephfs
Запишите секретный ключ администратора:
# cat /etc/ceph/ceph.client.admin.keyring
#У меня это ....
client.admin]
key = AQCzKE9f0x/DARAAFbJfwyAAIMgRoFSFVEJObw==
# Пример монтирования:
mount -t ceph 10.0.0.5:6789:/ /mnt/cephfs -o name=admin,secret=AQCzKE9f0x/DARAAFbJfwyAAIMgRoFSFVEJObw==
# Пример монтирования не показывать пароль:
mount -t ceph nod0.inc:6789:/ /mnt/cephfs -o name=admin,secretfile=/etc/ceph/adminkey
mount -t ceph nod1:6789,nod2:6789,nod0:6789:/ /mnt/cephfs -o name=admin,secretfile=/etc/ceph/admin.secret,noatime
# С использование ceph-fuse
sudo ceph-fuse -k /etc/ceph/ceph.client.admin.keyring -m nod0.inc:6789 /mnt/cephfs
sudo ceph-fuse -k /etc/ceph/ceph.client.admin.keyring -m 78.140.237.74:6789 /mnt/cephfs
###fstab
#10.0.0.5:6789:/ /mnt/cephfs ceph name=admin,secretfile=/etc/ceph/adminkey,noatime,_netdev 0 2
#id=admin,conf=/etc/ceph/ceph.conf /opt/mycephfs fuse.ceph defaults,_netdev 0 0
17. dashboard и всякая гадость
Хочу dashboard потом посмотрим.... Enable Ceph Dashboard Enable the Ceph Dashboard module: sudo ceph mgr module enable dashboard sudo ceph mgr module ls Generate self signed certificates for the dashboard: sudo ceph dashboard create-self-signed-cert Create a user for Dashboard: sudo ceph dashboard ac-user-create admin 'LBPbQ9w9nFQnknfn!' administrator Enabling the Object Gateway Management Frontend: sudo radosgw-admin user create --uid=admin --display-name='Ceph Admin' --system Finally, provide the credentials to the dashboard: sudo ceph dashboard set-rgw-api-access-keysudo ceph dashboard set-rgw-api-secret-key If you are using a self-signed certificate in your Object Gateway setup, then you should disable certificate verification: sudo ceph dashboard set-rgw-api-ssl-verify False
18. если нужно будет все снести
ceph-deploy purge {ceph-node} [{ceph-node}]
ceph-deploy purgedata {ceph-node} [{ceph-node}]
ceph-deploy forgetkeys
rm ceph.*
19. s3 bucket - пользователь
sudo radosgw-admin user create --uid="testuser" --display-name="First User" - добавить пользователя
{
"user_id": "testuser",
"display_name": "First User",
"email": "",
"suspended": 0,
"max_buckets": 1000,
"auid": 0,
"subusers": [],
"keys": [
{
"user": "testuser",
"access_key": "3ZLDRWY8EP0ZWQCDYWEJ",
"secret_key": "YRzxIzqWGs7CoavSaWM2UOmZXitJKpKjqUKCTQkr"
}
],
"swift_keys": [],
"caps": [],
"op_mask": "read, write, delete",
"default_placement": "",
"placement_tags": [],
"bucket_quota": {
"enabled": false,
"check_on_raw": false,
"max_size": -1,
"max_size_kb": 0,
"max_objects": -1
},
"user_quota": {
"enabled": false,
"check_on_raw": false,
"max_size": -1,
"max_size_kb": 0,
"max_objects": -1
},
"temp_url_keys": [],
"type": "rgw",
"mfa_ids": []
}
20. python и s3bucket
sudo apt install python-boto - установим python-boto
vi s3test.py - создадим скрипт
--------------------------------
import boto.s3.connection
access_key = 'I0PJDPCIYZ665MW88W9R'
secret_key = 'dxaXZ8U90SXydYzyS5ivamEP20hkLSUViiaR+ZDA'
conn = boto.connect_s3(
aws_access_key_id=access_key,
aws_secret_access_key=secret_key,
host='{hostname}', port={port},
is_secure=False, calling_format=boto.s3.connection.OrdinaryCallingFormat(),
)
bucket = conn.create_bucket('my-new-bucket')
for bucket in conn.get_all_buckets():
print "{name} {created}".format(
name=bucket.name,
created=bucket.creation_date,
)
--------------------------------
У меня вышло вот так
import boto.s3.connection
access_key = '3ZLDRWY8EP0ZWQCDYWEJ'
secret_key = 'YRzxIzqWGs7CoavSaWM2UOmZXitJKpKjqUKCTQkr'
hostname = '10.0.0.4'
portnamber = 80
ceph.example.com
conn = boto.connect_s3(
aws_access_key_id=access_key,
aws_secret_access_key=secret_key,
host=hostname, port=portnamber,
is_secure=False, calling_format=boto.s3.connection.OrdinaryCallingFormat(),
)
bucket = conn.create_bucket('my-new-bucket')
for bucket in conn.get_all_buckets():
print "{name} {created}".format(
name=bucket.name,
created=bucket.creation_date,
)
Выполнил:
python s3test.py
Ответ:
my-new-bucket 2020-09-03T10:42:41.238Z
21. s3cmd - клиент подключения / управления bucket
s3cmd s3cmd --configure - настройка конфига (в каталоге пользователя у нас будет создан файл .s3cfg) s3cmd mb s3://bucket_name - создать backet s3cmd put --acl-public file_name.txt s3://bucket_name - отправить файл file_name.txt в bucket_name который будет доступен всем s3cmd ls - получить список bucket s3cmd ls s3://name_bucket - получить список объектов в name_bucket s3cmd del s3://bucket/object - удалить объект Пример для бекапа \ sync: s3cmd --acl-private --bucket-location=EU mb s3://bucket_name - создать backet s3cmd get s3://name_bucket/file_name.txt my_local_file.txt - выгрузить объект s3://name_bucket/file_name.txt и сохранит в текущем каталоге с именем my_local_file.txt s3cmd --acl-private --bucket-location=EU --guess-mime-type --delete-removed sync /local/backup/ s3://bucket_name/backupfromserv1 Ключ -"-acl-private" означает, что доступ к файлам будет только у нас. С помощью "--bucket-location=EU" мы указываем регион (в данном случае Европу, аточнее Ирландию). Опция "--guess-mime-type" обозначает, что MIME-тип содержимого будет подбираться автоматически, исходя из расширения файла. А чтобы файлы сами удалились из S3-хранилища, если они исчезают в локальной папке, используется ключ "--delete-removed". s3cmd sync s3://bucket_name/backupfromserv1 /local/backup/ - восстановить из резервной копии s3cmd ls s3://bucket_name - посмотреть, что хранится в bucket'е Добавляем команду на бэкап в cron и наслаждаемся самым надежным бэкапом, который только можно представить.
haproxy
nano /etc/haproxy/haproxy.cfg
-----------------------------
frontend ceph_front
bind 0.0.0.0:80
default_backend ceph_back
backend ceph_back
balance source
server radosgw01 127.0.0.1:7480 check
-----------------------------